GNOME 46 just released, and with it comes TinySPARQL 3.7 (aka Tracker SPARQL) and Tracker Miners 3.7. Here’s what I’ve been involved with this month in those projects.
Google Summer of Code
It wasn’t my intention to prepare another internship before the last one was even finished. It seems that in GNOME we have fewer projects and mentors than ever – only eight ideas this year, compared to fourteen confirmed projects back in 2020. So I proposed an idea for TinySPARQL, and here we are.
The idea, in brief: I’ve been working a bit with GraphQL recently, which doesn’t live up to the hype, but does have nice query frontends such as GraphQL Playground and graphiql that let you develop and test queries in realtime. This is a screenshot of graphiql:
In TinySPARQL, we have a commandline tool tracker3 sparql which can run queries and print the results. This is handy for developing testing queries independently of the app logic, but it’s only useful if you’re already something a SPARQL expert.
What if TinySPARQL had a web interface similar to the GraphQL Playground?
Besides running queries and showing the output, this could have example queries, resource browsing, as-you-type error checks, integrated documentation, and more fun things listed in this issue. My hope is this would encourage more folk to play around with the data running interesting queries and would help to visualize what you can do with a detailed metadata index for your local content. I think a lot of people see Tracker Miner FS as a black box that does basic string matching, and not the flexible database that it actually is.
Lots of schools teach HTML and JavaScript so this project seems like a great opportunity for an intern to take ownership of and show their skills. Applications are open until 2nd April, and we’ll be running a couple of online meetups later this week (Thursday 21st and/or Friday 22nd March) to help you create a good application. Join the #tracker:gnome.org Matrix room if you’re interested.
By the way, it’s only recently been possible to separate your queries from the rest of your app’s code. I wrote about this here: Standalone SPARQL Queries. The TrackerSparqlStatement class is flexible and fun and you can read your SPARQL statements straight from a GResource file. If you used libtracker-sparql around 1.x you’ll remember a horrible thing named TrackerSparqlBuilder – the query developer experience has come a long way since then.
New security features
There are some new features this cycle thanks to hard work by Carlos. I’ll let him write up the fun parts. One part that’s not much fun, is the increased security protections for tracker-extract. The background here is that tracker-extract uses many different media parsing libraries, and if any one of those libraries shipped by your distro contains a vulnerability, that could potentially be exploited by getting you to download a malicious file which would then be processed by tracker-extract.
We have no evidence that anyone’s ever actually done this. But there was a writeup on how it could happen recently using a vulnerability in a library named libcue which nobody is maintaining, including a clever bypass of the existing SECCOMP protection. Carlos did a writeup of this on his blog: On CVE-2023-43641.
With Tracker Miners 3.7, Carlos extended the existing SECCOMP sandbox to cover the entire extractor process rather than just the processing thread, which prevents that theoretical line of attack. And, he added an additional layer of sandboxing using a new kernel API called Landlock, which lets a process block itself from accessing any files except those it specifically needs.
From my perspective it’s rather draining to help maintain the sandboxing. When it works, nobody notices. When the sandboxing causes issues, we hear about it straight away. And there are plenty of issues! Even the build-time configuration for Landlock seems to need hours of debate.
SECCOMP works by denying access to any kernel APIs except those legitimately needed by the extractor process and the libraries it uses. Linux has 450+ syscalls and counting, and we maintain an explicit allowlist. Any change to GLibc, GIO, GStreamer or any media parsing library may then change what syscall gets used. If an unexpected syscall is called the tracker-extract process is killed with SIGSYS, which gets reported as a crash in just the same way as segfaults caused by programming errors.
It’s draining to support something that can break randomly by things that are out of our control. What else can we do though?
What’s next?
It might seem like openQA testing and desktop search are unrelated, but there is a clear connection.
Making reproducible integration tests for a search engine is a very hard problem. Back last decade I worked on the project’s Gitlab CI setup and “functional tests”. These tests live in the tracker-miners.git source tree, and run the real the crawler and extractor, testing that we can create a file named hello.txt, wait for it to be indexed and search for its contents. Quite a step forwards from unreproducible “works on my machine” testing that came before, but not representative of real use cases.
Real GNOME users do not have a single file in their home dir named hello.txt. Rather they have GBs or TBs of content to be indexed, and they have expectations about what constitutes the “best match” for a given search term.
I’m not interested in working to solve this kind of thing until we can build regression tests so that things don’t just work, but keep working in the long term. Hence, the work-in-progress gnome_search test for openQA, and the example-desktop-content repo. This is at the “working prototype” stage, and is now ready for some deeper thinking about what specific scenarios we want to test.
Some other things that may or may not happen next cycle in desktop search, depending on whether people care to help push them forwards:
beginning the rename: this won’t happen all at once, but we want to start calling the database TinySPARQL, and the indexer something else, still to be decided. (Ideas welcome!)
a ‘limiter’ to detect when a directory contains so much content that the indexer would burn significant CPU and IO resource trying to index everything up front (which requires corresponding UI changes so that there’s a way to “opt in” to indexing such locations on demand)
indexing the whole $HOME directory (which I personally don’t want to land without the ‘limiter’ in place, but let’s see)
One thing is certain, next month things are certainly going to slow down for me… I’m holiday for two full weeks over Easter, spring is coming and I plan to spend most of my time relaxing in a hammock. Hopefully we’ve sowed a lot of seeds this month which will soon turn into flowers.
Some months you work very hard and there is little to show for any of it… so far this is one of those very draining months. I’m looking forward to spring, and spending less time online and at work.
Rather than ranting I want to share a couple of things from elsewhere in the software world to show what we should be aiming towards in the world of GNOME and free operating systems.
Before we even started writing the database, we first wrote a fully-deterministic event-based network simulation that our database could plug into. … if one particular simulation run found a bug in our application logic, we could run it over and over again with the same random seed, and the exact same series of events would happen in the exact same order. That meant that even for the weirdest and rarest bugs, we got infinity “tries” at figuring it out, and could add logging, or do whatever else we needed to do to track it down.
The text is hyperbolic, and for some reason they think it’s ok to work with Palantir, but its an inspiring read.
Secondly, a 15 minute video which you should watch in its entirety, and then consider how the game development world got so far ahead of everyone else. Here’s a link to the video.
This is the world that’s possible for operating systems, if we focus on developer experience and integration testing across the whole OS. And GNOME OS + openQA is where I see some of the most promising work happening right now.
Of course we’re a looooong way from this promised land, despite the progress we’ve made in the last 10+ years. Automated testing of the OS is great, but we don’t always have logs (bug), the image randomly fails to start (bug), the image takes hours to build, we can’t test merge requests (bug), testing takes 15+ minutes to run, etc. Some of these issues seem intractable when occasional volunteer effort is all we have.
Imagine a world where you can develop and live-deploy changes to your phone and your laptop OS, exhaustively test them in CI, step backwards with a debugger when problems arise – this is what we should be building in the tech industry. A few teams are chipping away at this vision – in the Linux world, GNOME Builder and the Fedora Atomic project spring to mind and I’m sure there are more .
Anyway, what happened last month?
Outreachy
This is the final month of the Outreachy internship that I’m running around end-to-end testing of GNOME. We already had some wins, there are now 5 separate testsuites running against GNOME OS, unfortunately rather useless at present due to random startup failures.
I spent a *lot* of time working with Tanju on a way to usefully test GNOME on Mobile. I haven’t been able to follow this effort closely beyond seeing a few demos and old blogs. This week was something of a crash course on what there is. Along the way I got pretty confused about scaling in GNOME Shell – it turns out there’s currently a hardcoded minimum screen size, and upstream Mutter will refuse to scale the display below a certain size. In fact upstream GNOME Shell doesn’t have any of the necessary adaptations for use in a mobile form factor. We really need a “GNOME OS Mobile” VM image – here’s an open issue – it’s unlikely to be done within the last 2 weeks of the current internship, though. The best we can do for now is test the apps on a regular desktop screen, but with the window resized to 360×720 pixels.
On the positive side, hopefully this has been a useful journey for Tanju and Dorothy into the inner workings of GNOME. On a separate note, we submitted a workshop on openQA testing to GUADEC in Denver, and if all goes well with travel sponsorship and US VISA applications, we hope to actually meet in person there in July.
FOSDEM
I went to FOSDEM 2024 and had a great time, it was one of my favourite FOSDEM trips. I managed to avoid the ‘flu – i think wearing a mask on the plane is the secret. From Codethink we were 41 people this year – probably a new record.
My main goal at FOSDEM was to make contact with other openQA users and developers, and we had some success there. Since then i’ve hashed out a wishlist for openQA for GNOME’s use cases, and we’re aiming to set up an open, monthly call where different QA teams can get together and collaborate on a realistic roadmap.
I saw some great talks too, the “Outreachy 1000 Interns” talk and the Fairphone “Sustainable and Longlasting Phones” were particular highlights. I went to the Bytenight event for the first time and and found an incredible 1970’s Wurlitzer transistor organ in the “smoking area” of the HSBXL hackspace, also beating Javi, Bart and Adam at Super Tuxcart several times.
I just published version 10.0 of the open source playlist generation toolkit, Calliope. This fixes a couple of long standing issues I wanted to tackle.
SQLite Concurrency
The first of these only manifest itself as intermittent Gitlab CI failures when you submitted pull requests. Calliope uses SQLite to cache data, and a cache may be used by multiple concurrent process. SQLite has a “Write-Ahead Log” journalling mode that should excel at concurrency but somehow I kept seeing “database is locked” errors from a test that verified the cache with multiple writers. Well – make sure to explicitly *close* database connections in your Python threads.
Content resolution with Tracker Miner FS
The second issue was content resolution using Tracker Miner FS, which worked nicely but very slowly. Some background here: “content resolution” involves finding a playable URL for a piece of music, given metadata such as the artist name and track name. Calliope can resolve content against remote services such as Spotify, and can also resolve against a local music collection using the Tracker Miner FS index. The “special mix” example, which generates nightly playlists of excellent music, takes a large list of songs taken from Listenbrainz and tries to resolve each one locally, to check it’s available and get the duration. Until now this took over 30 minutes at 100% CPU.
Why so slow? The short answer is: cpe tracker resolve was not using the Tracker FTS (Full Text Search) engine. Why? Because there are some limitations in Tracker FTS that means we couldn’t use it in all cases.
About Tracker FTS
The full-text search engine in Tracker uses the SQLite FTS5 module. Any resource type marked with tracker:fullTextIndexed can be queried using a special fts:match predicate. This is how Nautilus search and the tracker3 search command work internally. Try running this command to search your music collection locally for the word “Baby”:
This feature is great for desktop search, but it’s not quite right for resolving music content based on metadata.
Firstly, it is doing a substring match. So if I search for the artist named “Eagles”, it will also match “Eagles of Death Metal” and any other artist that contains the word “Eagles”.
Secondly, symbol matching is very complicated, and the current Tracker FTS code doesn’t always return the results I want. There are at least two open issues, 400 and 171 about bugs. It is tricky to get this right: is ' (Unicode +0027) the same as ʽ (Unicode +02BD)? What about ՚ (Unicode +055A, the “Armenian Apostrophe”)? This might require some time+money investment in Tracker SPARQL before we get a fully polished implementation.
My solution the meantime is as follows:
Strip all words with symbols from the “artist name” and “track name” fields
If one of the fields is now empty, run the slow lookup_track_by_name query which uses FILTER to do string matching against every track in the database.
Otherwise, run the faster lookup_track_by_name_fts query. This uses both FTS *and* FILTER string matching. If FTS returns extra results, the FILTER query still picks the right one, but we are only doing string matching aginst the FTS results rather than the whole database.
Some unscientific profiling shows the special_mix script took 7 minutes to run last night, down from 35 minutes the night before. Success! And it’d be faster still if people can stop writing songs with punctuation marks in the titles.
Yesterday’s Special Mix.
Standalone SPARQL queries
You might think Tracker SPARQL and Tracker Miners have stood still since the Tracker 3.0 release in 2020. Not so. Carlos Garnacho has done huge amounts of work all over the two codebases bringing performance improvements, better security and better developer experience. At some point we need to do a review of all this stuff.
Anyway, precompiled queries are one area that improved, and it’s now practical to store all of an apps queries in separate files. Today most Tracker SPARQL users still use string concatenation to build queries, so the query is hidden away in Python or C code in string fragments, and can’t easily be tested or verified independently. That’s not necessary any more. In Tracker Miners we already migrated to using standalone query files (here and here). I took the opportunity to do the same in Calliope.
The advantages are clear:
no danger of “SPARQL injection” attacks, nor bugs caused by concatenation mistakes
a query is compiled to SQLite bytecode just once per process, instead of happening on every execution
you can check and lint the queries at build time (to do: actually write a SPARQL linter)
you can run and test the queries independently of the app, using tracker3 sparql --file. (Support for setting query parameters due to land Real Soon).
The only catch is some apps have logic in C or Python that affects the query functionality, which will need to be implemented in SPARQL instead. It’s usually possible but not entirely obvious. I got ChatGPT to generate ideas for how to change the SPARQL. Take the easy option! (But don’t trust anything it generates).
Next steps for Calliope
Version 10.0 is a nice milestone for the project. I have some ideas for more playlist generators but I am not sure when I’ll get more time to experiment. In fact I only got time for the work above because I was stuck on the sofa with a head-cold. In a way this is what success looks like.
Musically this has been a fun month. One of my favourite things about living in Galicia is that ska-punk never went out of fashion here and you can legitimately go to a festival by the sea and watch Ska-P. Unexpectedly brilliant and chaotic live show. I saw an interview recently where Angelo Moore of Fishbone was asked by a puppet what his favourite music is, and he answered: “I like … I like the Looney Tunes music”. Same energy.
I wrote already this month about my DIY media server and the openQA CLI tool. This post contains some brief thoughts about Nushell and then some lengthy thoughts about the future of the Web. Enjoy!
Nushell everywhere
I read a blog by serial shell innovator JT entited “The case for Nushell”. I’ve been using Nushell for data-focused work for a while and the post inspired me to make it my default shell in a few places.
Nushell is really comfortable to use these days, it’s very addictive the first time you construct a one-liner to pretty-print some JSON or XML, select the fields you want and output a table as Markdown that you can paste straight into a Gitlab issue. My only complaint is the autocomplete isn’t quite as good as the Fish shell yet. (And that you can’t type rm -R… like chown and chmod only accept -R, and now rm only accepts a lower case -r, how am I supposed to remember that guys???)
I have a load of arcane Bash knowledge that I guess I’ll have to hang onto for a while yet, particularly as my job mostly involves SSH’ing into strange old machines from the 1990s. Perhaps I can try and contribute Nushell binaries that run on HP-UX and Solaris. (For the avoidance of doubt, that previous sentence is a joke).
Kagi Small Web
There’s a new search engine on the block called Kagi which is marketed as “premium search engine”, you pay $0.05 per search, and in return the results are ad-free.
I like this idea. I signed up for the free trial 100 searches, and I haven’t got far with them.
It turns out most of the web searches I do, are things I could search on a specific site if I wasn’t so lazy. For example I search “rust stdio” when I could go to the Rust documentation on my local machine and search there. Or I search for a programming problem when I could clearly just search StackOverflow itself. DuckDuckGo has made me lazy; adding a potential $0.05 cost to searches firstly makes you realize how few you actually need to do. Maybe this is a good thing.
Anyway, Kagi. They just launched something named Kagi Small Web, which is announced here:
Kagi Small Web offers a fresh approach by promoting recently published content from the “small web.” We gather new content, published within the last week, from a handpicked list of blogs and surface it in multiple ways:
Directly within Kagi search results for applicable queries (existing Kagi members do not need to do anything, this will be automatic)
Via the new Kagi Small Web website
Through the Kagi Small Web RSS feed
Via our Search API, where results are now part of the news enrichment API
Initially inspired by a vibrant discussion on Hacker News, we began our experiment in late July, highlighting blog posts from HN users within our search results. The positive feedback propelled the initiative forward. Today, our evolving concept boasts a curated list of nearly 6,000 genuine websites featuring people with a wide variety of interests.
When I first saw this my mind initially jumped to the problematic parts. Who are these guys to suddenly define what the Small Web is, and define it as a a club of some 6,000 websites chosen by Hackers News? All sites must be in English, so is the Web only for English speakers now?? More importantly, why is my site not on the list? Why wasn’t I consulted??
There’s also something very inspiring about the project. I try to follow the rule “something is better than nothing”, and this project is a pretty bold step forwards, which inspired a bunch of thoughts about the future of The Web.
Google Search is Dying
Since about 2000, when you think of the Web, you think of Google.
Google Search has been dying a slow, public death for about the last ten years. Google has been too big to innovate since the early 2010s (with one important exception, the Emoji Kitchen).
Google Search remained king until now for two reasons: one, their tech for turning hopelessly vague search queries into useful results was better than anyone’s in the industry, and two, as of 2023, almost nobody else can operate at the scale needed to index all of the text on the Web.
I guess there’s a third reason too, which is spending billions of $$$ to be the default search provider nearly everywhere, to the point that the USA is running an antitrust hearing against them, but let’s focus on the technical aspects.
The current fad for large language models is going to bring big changes to the Web, for better or worse. One of those is that “intent analysis” is suddenly much easier than it was. Note, I’m not talking about prompting an LLM with a question and presenting the randomly generated output as an answer. I’m talking about taking unstructured text, such as “trains to London” and turning it into an actionable query. A 1990’s era search engine would throw away the “to” return any website that contained “trains” and “London”. Google Search shows a table of live departure times for trains heading to London. (With some less useful things above and below, since this is the Google Search of 2023).
A small LLM such as Vicuna can kinda just DO this stuff, not perfectly of course, but its an order of magnitude easier than a decade ago. Perhaps Google kept their own LLM research internal for so long for fear of losing exactly this edge? The “We have no moat” memo suggests fear.
Onto the second thing, indexing all the content on the Web. LLMs don’t make this easier. They make it impossible.
Its now so easy to generate human-like text on the Web using machines, that it doesn’t make sense to index all the text on the Web any more. Much of it is already human-generated generated garbage aiming to game search ranking algorithms (see “A storefront for robots” for fun examples).
Very soon 99% of text on the web will be machine generated garbage. Welcome to the dark forest.
For a short time I was worried about this, but I think it’s a natural evolution of the Web. This is the end of the Olde World Wide Web. What comes next?
There is more than one Small Web
If you’ve read this far, firstly, thanks and well done, in 2023 its hard to read so many paragraphs in one go! I didn’t even put in single video.
Let me share the insight I had on thinking over Kagi Small Web. Maybe it’s obvious and maybe it isn’t.
A search engine of 6,000 websites is small-scale enough that one person could conceivably run it.
Let’s go back a step. How do you deal with a Web that’s 99% machine-generated noise? I imagine Google will try to solve this by using language models to detect if the page was generated by a language model, triggering another fairly pointless technological arms race against the spammers who will be generating this stuff. This won’t work very well.
The only way for humans to make sense of the new Dark Forest Web is to have lists of websites, curated by humans, and to search through those when we want to find information.
If you’re old you know that this isn’t a new idea. In fact, we kinda had all of this stuff in the form of web rings, link pages on other people’s websites, bookmarking services, link sites like Digg, Fark and Reddit, RSS feeds and feed readers. If you look at Kagi Small Web reader site it’s literally a web ring. It’s StumbleUpon. It’s Planet GNOME. But through the lens of 2023, it’s also something new.
So I’m not going to start reading Kagi’s small web, though it may be great. And I’m going stop capitalising “small web”, because I think we’re going to curate millions of these collectively, in thousands of languages, in infinite online communities. We’re going to have open source tools for searching and archiving high quality online content. Who knows? Perhaps in 10 years we’ll have small web search tools integrated into GNOME.
You know the feeling of actually coding something, a new library which doesn’t exist yet but you know exactly how it should look and you just need to chip away at the problem space until its final form appears ?
I was really lacking any creative flow recently and decided to flesh out the libgnomesearch library that I proposed a while ago, which my colleague Kaspar Matas already made a start at developing.
The purpose of this library is to consolidate existing search code that currently lives in Nautilus, GTK, GNOME Shell and various core apps. There are some interesting designs for improving GNOME’s desktop search functionality, and I suspect it will be easier to prototype and implement these if there is a single place to make the changes.
I dedicated some evenings and weekends to the fun part of building an API and example app, and this is the result. Some code, some documentation, and a demo app:
To state the obvious : it’s not finished and it has bugs!
I can’t spend work time on this and probably won’t have much more volunteer time for it either, so let’s see what happens next. If this sounds like a project you are interested in continuing, get in touch – and if you are at GUADEC 2023 then we can chat there!
The GSoC 2021 cohort has just been announced. There’s a fantastic list of organisations involved, including GNOME, and I’m happy that this year two of those projects will be based around Tracker.
We were lucky to have several promising candidates. I want to shout out Nitin in particular for getting really involved with Tracker and making some solid contributions too. I want to remind all GSoC applicants of two things. Firstly that a track record of high quality open source contributions is something very valuable and always an advantage when applying for jobs and internships. Including next year’s GSoC 🙂 And secondly that if 5 folk propose the same project idea, only one can be chosen, but if 5 different project ideas arrive then we may be able to choose two or even three of them.
I also want to highlight the great work Daniele Nicolodi has been doing recently on the database side of Tracker. If you want a SPARQL 1.1 database and don’t want to go EnterpriseTM Scale, your options are surprisingly limited, and one goal of the Tracker 3 work was to make libtracker-sparql into a standalone database option. Daniele has moved this forward, already getting it running on Mac OS X and cleaning up a number of neglected internal codepaths.
I hope the increased involvement shows our developer experience improvements are starting to pay dividends. More eyes on the code that powers search in GNOME is always a good thing.
One of my favourite discoveries of 2020 is Joplin, an open, comprehensive notebook app. I’m slowly consolidating various developer journals, Zettelkasten inspired notes, blog drafts, Pinboard bookmarks and abstract doodles into Joplin notebooks.
Now it’s there I want to search it from the GNOME Shell overview, and that’s pretty fun to implement.
It’s available from here and needs to be installed manually with Meson. Perhaps one day this can ship with Joplin itself, but there are few issues to overcome first:
It’s not yet possible to open a specific note in Joplin. I suggested adding a commandline option and discovered they plan to add x-callback-url support, which will be great once there’s a design for how it should work.
The search provider also appears as an application in the Shell. I think a change in GNOME Shell is needed before we can hide this.
Hoping to make better use of this expansive set of thought-provoking articles, hilarious videos and expired domain names, I wrote a minimal search provider for GNOME Shell.
If you’re happy to meson install some Python scripts, then you can use it too! The search provider installs a systemd timer unit which checks for new bookmarks every hour, and downloads them into a Whoosh search index. I chose Whoosh because it’s fun to try new search engines, and my opinion is that it’s fast, powerful, and a little heavy on the disk space usage — my bookmarks take up 7MB in a JSON file but 17MB in the Whoosh index.
A secondary purpose of this effort is to show how easy it is to make search providers. It took me about 8 hours to make this. Feel free to copy and paste for your own search providers, and use the CLI test tool in my desktop-search repo when testing them.
What other services would you like to see integrated into GNOME Shell as search providers? Next on my list might be notes from Joplin.
In previous post we looked at the Semantic Web, the semantic desktop, and how it can be that after 20 years of development, most desktop search engines still provide little more than keyword matching in your files.
History shows that the majority of users aren’t excited by star ratings, manual tagging or inference. App developers mostly don’t want to converge on a single database, especially if the first step is to relinquish control of their database schema.
So where do we go from here? Let’s first take a look at what happened in search outside the desktop world in the last 20 years.
The companies listed above spend billions of US dollars per year on research, so it’d be surprising if they didn’t have the edge over those of us who prioritize open technologies. We need to accept that we’re unlikely to out-innovate them. But we can learn from them.
The way people interact with a search engine is dramatically similar to 20 years ago. We type our thoughts into a text box. Increasingly people speak a question to a voice assistant instead of typing it, but internally it’s processed as text. There are exceptions to this, such as Reverse Image Search and Shazaam, and if you work for the Government you have advanced and dangerous tools to search for people. But we’re no nearer to Minority Report style interfaces, despite many of the film’s tech predications coming true, and Dynamicland is still a prototype.
The biggest change therefore is how the search engines and assistants process your query once they receive it.
Dynamicland: A fascinating prototype for the future of computing
Behind the <input type="text">
Text is still our primary search interface, but these days there is a lot more than keyword matching going on when you type something into a search engine, or speak into a voice assistant.
These tools are useful but I rarely see them used by non-experts. However everyone benefits from query expansion, which includes word stemming, spelling correction, automated translation and more.
Natural language processing
In 2013, Google announced the “Hummingbird” update, described as the biggest change to its search algorithm in its history. Google claimed that it involves “paying more attention to all the words in the sentence”, and used the epithet “things, not strings”. SEO site moz.com gives an intesting overview, and uses the term Google seem to avoid — Semantic Search.
How does it work? We can get some idea by studying a service Google provides for developers called Dialogflow, described as “a natural language understanding platform”, and presumably built out of the same pieces as Hummingbird. The most interesting part is the intent matching engine, which combines machine learning and manually-specified rules to convert “How is the weather in Cambridge” into two values, one representing the intent of “query weather” and the other representing the location as “Cambridge, UK.” That is, if you’re British. If you’re based elsewhere, you’ll get results for one of the world’s many other Cambridges. We know Google collects data about us, which is a controversial topic but also helpful to translate subjective phrases into objective data such as which Cambridge I’m referring too.
As we enter the age of voice assistants, natural language processing becomes a bigger and bigger topic. As well as Google’s Dialogflow, you can use Microsoft’s LUIS or Amazon’s Comprehend, all of which are proprietary cloud services. MyCroft maintain some open source intent parsing tools, and perhaps there are more — let me know!
The language processing in the Hummingbird update brought to the forefront a feature launched a year earlier called Knowledge Graph, which provided results as structured data rather than blue hyperlinks. It wasn’t the first mainstream semantic search engine — maybe Wolfram Alpha gets that crown — but it was a big change.
Wolfram Alpha claims to work with manually curated data. To a point, so does Google’s Knowledge Graph. Google’s own SEO guide asks us to mark up our websites with JSON-LD to provide ‘rich search results’.
DuckDuckGo was also early to the ‘instant answers’ party. Interestingly their support was developed largely in the open. You can see a list of their instant answers here, and see the code on GitHub.
Back to the Desktop Future
Web search involves querying every computer on the Web, but Desktop search involves searching through just one. However, it’s important to see search in context. Nearly every desktop user interacts with a web search engine too and this informs our expectations.
Unsurprisingly, I’m going to recommend that GNOME continues with Tracker as its search engine and that more projects try it out. I maintain a Wishlist for Tracker (which used to be a roadmap, but Jeff inspired me to change it ;). Our wishlist goals are mostly for Tracker to get better at doing the things it already does. Our main focus has to be stability, of course. I want to start a performance testing initiative during the GNOME 40 cycle. This would help us test out the speedups in Tracker Miners master branch, and catch some extractor bugs in the process. Debian/Ubuntu packaging and finishing the GNOME Photos port are also high on the list.
When we look at where desktop search may go in the next 10 years, Tracker itself may not play the biggest role. The possibilities for search are a lot deeper. Six months ago I asked on Reddit and Discourse for some “crazy ideas” about the future of search. I got plenty of responses but nothing too crazy. So here’s my own attempt.
Automated Tagging
Maybe because I grew up with del.icio.us I think tagging is the answer to many problems, but even I’ve realised that manually tagging your own photos and music is a long process that even I’m not very interested in doing.
A forum commenter noted that AI-based image classification is now practical on desktop systems, using onnxruntime. The ONNX Model Zoo contains various neural nets able to classify an image into 1,000 categories, which we could turn into tags. Another option is the FANN library if suitable models can be found or trained.
This would be great to experiment with and could one day be a part of apps like GNOME Photos. In fact, Tobias already proposed it here.
Time-based Queries
The Zeitgeist engine hasn’t seen much development recently but it’s still around, and crvi recently rejuvenated the Activity Journal app to remind us what Zeitgeist can do.
We talked about integrating Zeitgeist with Tracker back in 2011, although it got stuck at the nitpicking stage. With advancements in Tracker 3.0 this would be easier to do.
The coolest way to integrate this would be via a natural language query engine that would allow searches like "documents yesterday" or "photos from 2017". A more robust way would be to use an operator like 'documents from:yesterday'. Either way, at some layer we would have to integrate data from Zeitgeist and Tracker Miner FS and produce a suitable database query.
Query Operators
Users are currently given a basic option — match keywords in a file via Nautilus or the Shell– and an advanced option of opening the Terminal to write a SPARQL query.
We should provide something in between. I once saw a claim that Tracker isn’t as powerful as Recoll as it doesn’t support operators. The problem is actually that we expose a less powerful interface. Support for operators would be relatively simple to implement. This could be a relatively straightforward project and could be implemented incrementally — a good learning project for a search engineer.
Suggestions
The full-text search engine in Tracker SPARQL does some basic query expansion in the form of stemming (turning ‘drawing’ into ‘draw’, for example) and removing stop words like ‘the’ and ‘a’. Could it become smarter?
We are used to autocomplete suggestions these days. This requires the user interface to ask the search backend to suggest terms matching a prefix, for example when I type mon the backend returns money, monkey, and any other terms that were found in my documents. This is supported by other engines like Solr. The SQLite FTS5 engine used in Tracker supports prefix matching, so it would be possible to query the list of keywords matching a prefix. Performance testing would be vital here as it would increase the cost of running a search.
Google takes autocomplete a step further by predicting queries based on other people’s search history and page contents. This makes less sense on the desktop. We could make predictions based on your own search history, but this requires us to record search history which brings in a responsibility to keep it private and secure. The most secure data is the data you don’t have.
Typo tolerance is also becoming the norm, and is a selling point of the Typosense search engine. This requires extra work to take a term like gnomr and create a list of known terms (e.g. gnome) before running the search. SQLite provides a ‘spellfix1’ module that should make this possible.
Suggestion engines can do lots more cool things, like recommending an album to listen to or a website to visit. This is getting beyond the scope of search, but it can reuse some of the data collected to power search.
The Cloud
When Google Desktop joined the list of discontinued Google products, the rationale was this:
People now have instant access to their data, whether online or offline. As this was the goal of Google Desktop, the product will be discontinued.
The life of a desktop developer is much simpler if we assume that all the user’s content lives on the Web. There are several reasons not to accept that as the status quo, though! There is a loss of privacy and agency that comes from giving your data to a 3rd party. Google no longer read your email for advertising purposes, but you still risk not being able to access important data when you need it.
Transferring data between cloud services is something we tried to solve before, the Conduit project was a notable attempt and later the GNOME Online Miners, and it’s still a goal today. The biggest blocker is that most Cloud services have a disincentive to let users access their own data via 3rd party APIs. For freemium, ad-supported services it doesn’t make sense to let users use your service while sidestepping the adverts that fund it.
Conduit, an early data sync app. Screenshot from Wikipedia
Another problem is that maintaining a local index of remote content is risky. It may result in unwanted network traffic — what if an indexer updates the index while the computer is tethered to an expensive 3G connection? It may result in huge local caches of documents the user doesn’t actually care about. It’s difficult to get defaults that work for everyone.
My suggestion is to make online sync features as explicit and opt-in as possible. We should avoid ‘invisible design’ here. If a user has content in Dropbox that they want available locally, they will search online for “how to search dropbox content in gnome.” We don’t need to enable it by default. If they want to search playlists from Spotify and Youtube locally, we can add an interface to do this in GNOME Music.
Another challenge is testing our integrations. It’s hard to automatically test code that runs against a proprietary web service, and at the moment we just don’t bother.
It’s early days for the SOLID project but their aim is to open up data storage and login across web services. I’d love it if this project makes progress.
Mashups, The Revenge
When I first got involved in Tracker, I was doing the classic thing of implementing a music player app, as if the world didn’t have enough. I hoped Tracker could one day pull data from Musicbrainz to correct the metadata in my local media files. Ten years ago we might have called this a “mashup”.
The problem with Tracker Miner FS correcting tags in the background is that it’s not always clear what the correct answer is. Later I discovered Beets, a dedicated tool that does exactly what I want. It’s an interactive CLI tool for managing a music database. GNOME Music has work-in-progress support for using metadata from Musicbrainz, and the Picard is still available too.
Tag editor in GNOME Music with suggestions from MusicBrainz, from app mockups
I think we’ll see more such organisation tools, focused on being semi-automated rather than fully automated.
GNOME Shell search
GNOME Shell’s search is super cool. Did you know you can do maths and unit conversions, via the Calculator search provider? Did you know you can extend it by installing apps that provide other search providers? You probably knew it’s completely private by default. Your searches don’t leave the machine, unlike on Mac OS. That’s why the Shell can’t integrate Web search results — we don’t want to send all your local searches to a 3rd party.
We can integrate more offline data sources there. I recently installed the Quick Lookup dictionary app which provides Wiktionary results. It doesn’t integrate with local search, but it could do, by providing an optional bundle of common Wiktionary definitions to download. Endless OS already does this with Wikipedia.
The DBus-federated API of Shell search has one main drawback — a search can wake up every app on your system. If a majority of apps store data with libtracker-sparql, the shell could use libtracker-sparql to query these databases directly and save the overhead of spawning each app. The big advantage of the federated approach, though, is that search providers can store data in the most suitable method for that data. I hope we continue to provide that option.
Natural Language
Could search get smarter still? Could I type "Show me my financial records from last year" and get a useful answer?
Natural language queries are here already, they just haven’t made it to the desktop outside of Mac OS. The best intent parsing engines are provided as Software as a Service, which isn’t an option for GNOME to use. Time is on our side though. The Mycroft AI project maintain two open source intent parsers, Adept and Padatious, and while they can’t yet compete with the proprietary services, they are only getting better.
What we don’t want to do is re-invent all of this technology ourselves. I would keep the natural language processing separate from Tracker SPARQL, so we integrate today’s technology which is mostly Python and JavaScript. A more likely goal would be a new “GNOME Assistant” app that could respond to natural language voice and text queries. When stable, this could integrate closely with the Shell in order to spawn apps and control settings. Mycroft AI already integrates with KDE. Why not GNOME?
This sounds like an ambitious goal, and it is, so let me propose a smaller step forwards. Mycroft allows developers to write Skills as does Alexa. Can we provide skills that integrate content from the desktop? Why should a smart speaker play music from Spotify but not from my hard drive, after all?
End to End Testing
Tracker SPARQL and Tracker Miners have automated tests to spot regressions, but we do very little testing from a user perspective. It requires a design for how search should really work in all of its corner cases — what happens if I search for "5", or "title:Blog", "12 monkeys", or "albums from 2015", or "documents I edited yesterday"?
As more complex features are added, testing becomes increasingly important, not just as “unit tests” but as whole-system integration tests, with realistic sets of data. We have the first step — live VM images — now we need the next step of testing infrastructure, and ,tests.
Funding
Funding is often key to big changes like the ones I’m going to describe below. A lot of development in GNOME happens due to commercial and charitable sponsorship, where contributors develop and maintain GNOME as part of their employment. Contribution also happens through volunteer effort, as part of research funding (see NLnet’s call for “Next Generation Search and Discovery” proposals), or sponsored efforts like GSoC and Outreachy. This is often on a smaller scale, though.
I want this series to highlight that search is a vital part of user experience and an important area to invest design and engineering effort. To answer the question “When can we have all this?”… you’re probably going to have to follow the money.
In conclusion…
This summer was an unusual situation where I had a free summer but a pandemic stopped me from going very far. Between river swims, beach trips and bikerides I still had a lot of free time for hacking – I counted more than 160 hours donated to the Tracker 3 effort in July and August.
I’m now looking for a new job in the software world. I’ll continue as a maintainer of Tracker and I promise to review your patches, but the future might come from somewhere else.
This is part 4 of a series. Part 1 is here, part 2 is here, and part 3 is here. Come back next week for my thoughts on the future of desktop search.
I thought this was going to be the last blog post about Tracker 3.0, but it got rather long and I decided to turn this appraisal of the project and its design into a post of its own. So, get ready for some praise and some criticism!
To criticise the design and implementation of a software project we first need to understand the project requirements. What it is trying to do? I’ve written some goals and non-goals for the Tracker search engine, and proposed them for inclusion in the README. Now I’m going to compare the goals with the reality. I am of course a biased observer, and I welcome you to make your own assessment, but let’s dive in!
Goal 1. Provide real-time searching and browsing of desktop content.
Tracker achieves this with a background indexing service and a fast SQLite database. Queries are fast and SQLite works well.
For apps that want to use search, we provide a flexible API but not a simple API. You can see this in use in Nautilus, and yes that’s 3 screenfuls of code.
I have seen complaints about slow queries, which can happen if the database becomes enourmous (multiple GBs) or becomes corrupted, but these are caused by things mostly out of our control — configuration mistakes, filesystem issues, or SQLite bugs. Where Tracker generates performance complaints it’s almost always related to the background indexing. More on that later.
Searching via GNOME Shell is not quite as fast as Tracker itself, as it relies on spawning many app processes to return results. If more apps start storing data using Tracker SPARQL then we may be able to optimise this in future, by having one process that queries all available databases.
Goal 2. Provide searchable data storage for desktop apps.
This was always a goal but pre-3.0 it was never widely adopted. I wrote about the drawbacks of the old ‘central data store’ model in the first post of the series. A big blocker for apps was that a central data store means a central database schema. It discourages innovation if adding a feature to your app requires first designing it, then negotating a schema change with the Ontology Overloads, and then trying it out and see how it works.
Tracker 3.0 brings independent app databases, so our story has improved a lot, but would you store app data with Tracker SPARQL? Why not use SQLite directly?
It’s true that SQLite is a great storage solution which you should definitely use if it suits you. Here’s what Tracker SPARQL provides that SQLite does not:
Implicitly handled database migrations. These are good for simple cases but comes with some restrictions, in particular any migration that may cause data loss is prohibited.
The ability to publish app data as a D-Bus endpoint. This is a speculative benefit for the moment, but may allow richer search results and more efficient Shell searches in future.
Similar read/write performance to raw SQLite. The SPARQL translation overhead isn’t huge and can often be mitigated altogether with prepared queries.
Noticibly higher disk space usage compared to SQLite. See below for more about why this happens.
A GObject-based API simpler than SQLite’s own
3. Allow full-text search within common document types.
To do full-text search we need to load data from different file formats. The tracker-extract-3 miner is responsible and you can see supported formats in the code. It’s rare that I see bugs about this part of the code aside from obscure crashes, in fact recently we’ve removed more formats than we added (goodbye DVI, MIDI, and source code formats).
Tracker’s full-text search capability is built on the SQLite FTS5 module. We currently don’t expose the full power of the FTS5 query language, only supporting basic keyword matches. And FTS5 is not particularly powerful compared to larger scale engines like Lucene. However, we are in line with state-of-the-art in other desktop search engines.
4. Allow advanced queries using a standard query language.
It’s fundamental to the current design of Tracker that we use SPARQL to query and update the database. The nice thing about that is it’s a well-maintained standard, reasonably intuitive and with tutorials available online. It even supports Federated Queries out-of-the-box, something neither SQL nor GraphQL manage.
However, SPARQL is not the easiest language to work with — there are many ways to typo a query so that it produces no results without telling you why. It’s also verbose. When porting GNOME Photos I ended up creating a templating system and some page-long queries.
The Tracker Miners don’t have special access to the database — they use SPARQL like everyone else, and we could in principle replace the current database engine with one of the many other SPARQL databases in existence, if there were any suitable alternatives, which there aren’t. SPARQL is quite a high barrier for a database engine to support and those that do support it are either too heavy for desktop/embedded, like JENA and Virtuoso, or unfinished / abandoned like 4store and Oxigraph. In the medium term we are likely to stick with our SQLite + SPARQL translation layer approach.
Removing the “advanced query language” requirement would allow switching to a different query API, which would require rewriting Tracker Miner FS and all apps that use Tracker. It also wouldn’t open up many more options. Xapian is a possibility, but its query engine is much more limited than our current one, and it has its own issues . The state of the art in open-source web search is the Lucene search engine, but it’s written in Java and, for better or worse, there would be controversy if GNOME came to depend on the Java runtime. A C++ port of Lucene exists, but is sufficiently abandoned as to still be hosted on SourceForge.net.
5. Be secure and private by default.
Despite the name, Tracker’s privacy credentials are strong. Your data never leaves your machine. Tracker’s index is as private as the rest of your home directory.
Tracker Miner FS scans files in the background, including inside the Downloads folder, which means a bug in tracker-extract and tracker-miner-fs could exploited by an attacker who tricks you into downloading a file that triggers the bug. The risk is highest in tracker-extract which actually opens the files and parses them. To mitigate this, tracker-extract is sandboxed using SECCOMP, preventing it from making network connections or reading files other than the one it’s processing. SECCOMP isn’t an ideal solution and causes occasionalbreakages, but it’s an important safeguard.
Of course there is also content-based sandboxing provided for Flatpak apps which I wrote about in Tracker 3.0: What’s New?
6. Be efficient enough for desktop and mobile use
Tracker Miner FS does well in profiling and is being optimised even more. You will find many reports online about “Tracker high CPU usage”, however. It’s a common enough question that we mention it in the FAQ. So is Tracker slow or not?
In almost all cases, reports of high CPU usage are due to internal bugs, rather than problems in the design. And these bugs can be terrible! It’s disappointing to hear about Tracker Miners causing people’s laptop fans to turn on for hours. Such issues are tricky to reproduce and have varied causes — bugs in the complex miner-fs/extractor code, bugs in dependencies, or misguided attempts to index huge dumps of text like source code. I’m yet to see one that indicates a fundamental design flaw, so for now the solution seems to be relying on users who experience these problems taking the time to help diagnose, reproduce and fix them.
As for disk space, I am not happy about the amount of space the index can consume, but it’s part of a speed/size tradeoff we made which is currently balanced towards speed. An empty Tracker SPARQL database can start at 3.2MB of disk space. We store the database schema in the database as RDF data, which is where most of this initial overhead comes from. We also use a data storage structure that’s optimised for RDF querying and serialisation, and it’s not the most efficient way to store data in SQLite.
7. Be maintainable by a small team.
This is the last item on the list but it should be the first, because an unmaintainable project will inevitibly meet a sad end.
The bus factor of Tracker is currently high.
There are around 30,000 lines of code in libtracker-sparql, mostly devoted to translating SPARQL to SQL. Carlos has focused a lot on rewriting this and it’s impressively clean — see the SPARQLparser in particular — but debugging it can be tricky as it generates very long, hard to read SQL queries. It has fairly good test coverage, but more tests would be great.
The Tracker Miner FS code is also complex with about 15,000 lines of code, and it is written with a combination of event callbacks, signals and virtual functions that I like to call “object-oriented spaghetti code”. I tried to graph the flow of execution once and gave up, so instead I spend an hour or more re-discovering how it works every time I do some work there. Deferring to the main loop as much as possible was important in the 2000s when single-core CPUs were still common and a long-running task in a daemon process could cause freezes in the graphical desktop. Now it just overcomplicates the code.
The multiple layers of inheritance are due to an unrealized goal of creating different kinds of content crawlers using the existing miner-fs code. In theory a TrackerMinerFS could crawl anything that can be represented as a GFile. In practice this has never been done. GNOME Online Miners do their own thing, and indeed online resources often don’t have a filesystem-like structure. In Tracker 3.0 we made libtracker-miner private, which enables us to refactor it without being concerned with API stability, and less likely that anyone can reuse it. Perhaps it’s time to simplify this part of the code.
I’ve tried to focus the majority of my energy on making the project more maintainable, something I wrote about already. In the Bugzilla days it was painful to review and test merge requests, but now we have GitLab and automated testing, most merge requests are simple and fun to review. Testing?
Tracker:
Tracker Miners:
The situation is OK but there is a long way to go.
Is Tracker the right answer?
A healthy project needs a stream of new contributors. I don’t currently see this happening.
One issue is that Tracker is not widely used outside GNOME. I try to maintain a list of apps and platforms using Tracker which illustrates this. (Please tell me if there’s something missing from the list!). That said, you can never be sure if more widespread use would help spread the work of maintenance, or simply bring more bug reports.
I write these blog posts in the hope that telling the reality of search in GNOME will bring some more understanding and involvement. On screen, the search interface is a small box, which makes it seem like the backend might be small and simple too — trust me that it isn’t.
It’s my opinion that Tracker remains the most suitable option for powering search in GNOME and further afield. (I’d be happy to be proved wrong, if the result is a better desktop search experience.) The main issue is fixing the last of the bugs that cause high resource usage. Look out soon for a testing initiative, in which we’ll try out recent speed improvements and try to catch and reproduce any remaining performance issues.
Come back next week for the final post, my thoughts on the next ten years of desktop search.
Gradually, the automated indexers got better. Google’s Pagerank algorithm was a breakthrough, using a statistical approach to determine ‘high quality’ websites and list those ones first.
The holy scriptures of the Web already proposed a different solution: not only should documents form webs, but the data inside them should too. Instead of a statistical model of ‘relevance’, the information would be present as structured data which you could search and query with a semantic search engine. In 1998 (the same year Google was founded) this idea was formalised as the Semantic Web.
Semantic What?
At this point, perhaps you are curious what ‘semantic search’ means, or perhaps your eyes glaze over at the sight of the world ‘semantic’, or perhaps memories of the 2000s have already caused your fists to clench in fury.
The article “Why Machine Learning Needs Semantics Not Just Statistics” gives a good introduction: the word ‘semantic’ is usually used to highlight that, for information retrieval tasks, our current statistical approaches are primitive.
In essence, they are akin to a human shown patterns in a pile of numbers and asked to flag future occurrences without any understanding of what those numbers represent or what the decision involves.
This is one of the reasons that current deep learning systems have been so brittle and easy to fool despite their uncanny power. They search for correlations in data, rather than meaning.
You may be thinking: I know that you can implement today’s machine learning using match boxes, but that link only tells me what semantic search isn’t, it doesn’t tell me what it is. If so, you’re on the money. In the years following its inception, a frequent criticism of the Semantic Web was that it was under-specified and too “utopian”.
Teaching machines to understand meaning
Does that sound utopian? Well, maybe. A lot of digital ink has been spilled on this topic over the last 20 years in often heated debates. However, there are some level headed voices.
One in particular was that of Aaron Swartz in the book “A Programmable Web”, published unfinished after his tragic death in 2013. In the introduction he notes:
The idea’s proponents do not escape culpability for these utopian perceptions… Instead of the “let’s just build something that works” attitude that made the Web (and the Internet) such a roaring success … they’ve convinced people interested in these ideas that the first thing we need to do is write standards.
Certainly, the most visible output of the Semantic Web effort has been various standards. Some early efforts are laughable: you would win an ‘obfusticated data format’ contest with JSON Triples, and all the data formats that use XML (a markup language) as a syntax are questionable at best, or, to quote Swartz again, “scourges on the planet, offenses against hardworking programmers”.
Later standards, particularly the JSON-LD data format and SPARQL query language are nice to use. But their most significant output is the RDF data model.
Here is some fan-mail that RDF has received over the years.
“It would be nice as a universal publishing format… far preferable to XML” (Aaron Swartz),
“A deceptively simple data model [which] trivializes merging of data from multiple sources” (Ian Davis)
“RDF is a shitty data model. It doesn’t have native support for lists. LISTS for fuck’s sake!” (Manu Sporny, creator of JSON-LD)
“Someone should describe RDF in 500 words or less as a generalization of INI. That note would spread understanding of RDF, which is simple but often described so abstractly that it seems complicated.” (Mark Evans, Lambda the Ultimate)
I think RDF is a reasonable data model which maps closely to the more intuitive document/key/value model. (Until you want to make a list). A more important criticism is whether a data model is what we really needed.
Clay Shirky discussed this in a scathing criticism of the Semantic Web from 2003:
Since it’s hard to make machines think about the world, the new goal is to describe the world in ways that are easy for machines to think about… The Semantic Web takes for granted that many important aspects of the world can be specified in an unambiguous and universally agreed-on fashion, then spends a great deal of time talking about the ideal XML formats for those descriptions.
For a detailed history of the Semantic Web, I recommend this Two Bit History article. Meanwhile. we need to go back to the desktop world.
From desktop search…
The 2000’s were also a busy time for GNOME and KDE. During the 90’s desktop search was an afterthought but in the new millenium, perhaps driven by advances on the web, lots of research took place.
Microsoft introduced WinFS (described by Gates as his biggest disappointment), Apple released Spotlight, even Google briefly weighed in and the open source world responded as we always do with several incompatible projects all trying to do the same thing.
Here’s a release timeline of some free desktop search projects:
I was still in school when Eazel created Nautilus and went bust shortly after. They created Medusa to provide full-text search for Nautilus, but without funding the project didn’t get past an 0.5 release. The Xapian library also formed around this time from a much older project. Both aimed to provide background indexing and full-text search, as did the later Beagle.
Tracker began in late 2005, introduced by Jamie McCracken and focusing on a “non-bloated implementation, high performance and low low memory usage”. This was mostly a response to Beagle’s dependency on the Mono C# runtime. Tracker 0.1 used MySQL or SQLite but instead of exposing the SQL engine directly it would translate queries from RDF Query, an XML format which predates SPARQL and is not something you want to type out by hand.
…to the Semantic Desktop
In 2006 the NEPOMUK project began. The goal was not a search engine but “a freely available open-source framework for social semantic desktops”, put even less simply a “Networked environment for personal ontology-based management of unified knowledge”. The project had €17 million of funding, much of it from the EU. The Semantic Web mindset had reached the free desktop world.
I don’t know where all the money went! But one output was NEPOMUK-KDE, which aimed to consolidate all your data in a single database to enable new ways of browsing and searching. The first commit was late 2006. Some core KDE apps adopted it, and some use cases, ideas and prototypes emerged.
Meanwhile, Nokia were busy contracting everyone in the Free Software world to work on Maemo, an OS for phones and tablets which would mark the start of the smartphone era had a certain fruit-related company not beaten them to it.
Nokia began funding six developers to work on Tracker (rather a rare event for a small open source project), and planned to use it for media indexing, search, and app data storage. There was a hackfest where many search projects were represented, and a standardisation effort called XESAM which produced a query language still in use today by Recoll.
Presentations about Tracker from this era show a now-familiar optimism. There’s a plea to store all app data in Tracker’s database, with implied future benefits: data sharing between apps, tagging, and the vague promise of “mashups”. There are the various diagrams of RDF graphs and descriptions of what SPARQL is. But there’s also an increasing degree of pragmatism.
By 2009 it was clear that there was no easy route to the Semantic Desktop valhalla. As search engines and desktop databases become more widely deployed, more and more complaints about performance started to appear and as a project destined for low-powered mobile devices, Tracker had to be extra careful in this regard.
Where are they now?
A decade since all this great tech was developed, why aren’t you using a Nokia smartphone today? The so-called Elopocalyse marks the end of ‘semantic desktop’ investment. Twenty years later, the biggest change to search in GNOME came from the GNOME Shell overview design, which uses a simple D-Bus API with no ‘semantic desktop’ tech in sight.
Tracker is still here, powering full-text search behind the scenes for many apps, and its longevity is a testament to Nokia’s decision to work fully upstream and share their improvements with everyone. Writing a filesystem indexer is hard and we’re lucky to build on the many years of investment from them. Credit also lies with volunteer maintainers who kept it going since Nokia gave up, particularly Martyn Russell and Carlos Garnacho, and everyone who has contributed to fixing, testing, translating and packaging it.
The Nepomuk data model is still used in Tracker. There was an attempt to form a community to maintain it after the funding ended, but their official home hasn’t seen an update in years and so Tracker keeps its own copy with our local modifications.
NEPOMUK-KDE did not make it to 2020. An LWN commentator summarizes the issue:
Nepomuk was 1 big, powerful, triplet-capable database that was meant to hold everything … it got too big and would corrupt sometimes and was slow and unstable…
So when the funding ran out, different ppl worked on it for a long time, trying to make it perform better. They got, well, somewhere, pretty much made the pig fly, but the tech was inherently too powerful to be efficient at the ‘simple’ use case it had to do most of the time: file name and full text search.
Tracker has had its share of performance issues, of course, but the early focus on mobile meant that these were mostly due to coding errors, rather than a fundamentally unsuitable design built around an enterprise-scale database. In 2014 KDE announced the replacementBaloo, a Xapian-based search engine that provides full-text search and little else.
So why does Tracker use RDF and SPARQL, when you can provide full text search without it?
It’s partly for “historical reasons” — it seemed a good idea at the time, and it’s still a good enough idea that there’s no point creating some new and non-standard interface from scratch. SPARQL is a good standard which suits its purpose and is in wide use in government and sciences.
RDF is still widely used too. The idea of providing structured data in websites caught on where there’s a business case for it. This mostly means adding schema.org markup so your content appears in Google, and Open Graph tags so it displays nicely in Facebook. There are also some big open data repositories published as RDF.
Whatever your perspective, it’s pretty clear that machines still don’t understand meaning, and the majority of data on the web is not open or structured. But that doesn’t mean there’s nothing we can do to improve the desktop search experience!
Come back next week for the final part of this series, my thoughts on the next ten years of Tracker and desktop search in general.
However, the shortcomings of the 2000’s era design have been clear for a while.
Back in 2005, around the time your grandparents first met each other on Myspace, it seemed a great idea to aggregate all the metadata we could find into a single database. The old tracker-store database from Tracker 2.x includes the search index created by Tracker Miner FS right next to user data stored by apps like Notes, Photos and Contacts. This was going to allow cool features like tagging people in your photo collection with their phone number and online status (before the surveillence-advertising industry showed how creepy that actually is). Ivan Frade’s decade-old talk “Semantic social desktop& mobile devices” is a great insight into the thinking of the time.
I’m going to dig into Tracker’s origins in a future article, but for now — note that “Security on graphs” is listed in Ivan’s presentation as a “to-do” item.
Security
In a world of untrusted Flatpak apps, “to-do” isn’t good enough. Any app that uses the system search service, even any app that stores RDF data with Tracker, requests a Flatpak D-Bus permission for org.freedesktop.Tracker1. This gives access to the entire tracker-store database, right down to the search terms indexed from ‘Documents’ folder. Imagine your documents as a savoury snack, stored in a big monolithic building. You accidentally install and run a malicious app, represented here as a hungry seagull…
To solve this, we had to make access control more granular. It didn’t make sense to retrofit this to tracker-store. During 2019, Carlos casually eliminated the monolithic tracker-store altogether and in its place implemented a desktop-wide distributed database, taking Tracker from a “public-by-default” model to “private-by-default”
The new libtracker-sparql-3 API lets apps store SPARQL data anywhere they like. You can keep it private, if you just want a lightweight database. Nautilus and Notes are already doing this, to store starred files and note data respectively.
If and when you want to publish data, it’s done by creating a TrackerEndpoint on DBus. Using a SPARQL federated query, one Tracker SPARQL database can pull data from multiple others in a single query. This, for example, allows Photos to merge photo metadata from the search index with album metadata stored in its own database. (I wrote more about this back in March).
The search index created by Tracker Miner FS is published at org.freedesktop.Tracker3.Miner.Files, but we don’t let Flatpak apps access this directly. A new Flatpak portal gates access to search based on content type. You can now install a music player app and let it search ONLY your music collection, where previously your options were “let the app search everything” or “break it”.
A clearer architecture
“I’m finally starting to “get” tracker 3. And it’s like an epiphany. “
If someone asked “What actually is Tracker?” I used to find it tricky to answer. We narrowed the focus down to two things: a lightweight database, and a search engine.
For the last 3 years we worked on separating these two concerns, and as of Tracker 3.0 we are done. Were we starting from search, we could find clearer names for the two parts than ‘tracker’ and ‘tracker-miners’, but we kept the repos and package names the same to avoid making the 2.x to 3.x transition harder for distributors.
The name “Tracker” refers to the overall project. You can use “GNOME Tracker” for clarity where needed. The project maintains two code repositories:
Tracker SPARQL: a distributed database, provided as a GObject C library and implementing the full SPARQL 1.1 query standard.
Tracker Miners: a content indexer for the desktop, providing the Tracker Miner FS system service and its companion Tracker Extract.
The tracker3 commandline tool can operate on any Tracker SPARQL database, and it has some extensions for searching and managing the Tracker Miner FS indexer.
Decentralisation
The headline feature is there’s one less reason to claim “Flatpak’s sandbox is a lie!”. Decentralisation brings more benefits too:
You can backup app data by running tracker3 export on the app’s SPARQL database. Useful for Notes, Photos and more.
Apps can bundle Tracker Miners inside Flatpak, allowing them to run on platforms that don’t ship a suitable version of Tracker Miners in the base OS.
Apps are no longer limited to the Nepomuk data model when storing data. Tracker Miner FS still uses the Nepomuk ontologies, but apps can write their own. Distributed queries work even across different data models.
Tracker’s test suite now sets up a private database for testing using public API, avoiding some hideous hacks.
Apps test suites can also set up private databases and even a private instance of the indexer. GNOME’s search and content apps have rather low test coverage at present. I suspect this is partly because the old design of Tracker made it hard to write good tests.
A distributed database is fundamentally a cool thing that you definitely need.
Stability
A system service, like a Victorian child, should be “seen and not heard”. Nobody wants the indexer to drain the battery, burn out the fan or lock up the desktop.
We prioritize any issue which reports the Tracker daemons have been behaving badly. In collaboration with many helpful bug reporters, we removed two codepaths in 3.0 that could trigger high CPU usage. One major change is we no longer index all plain text files, only those with an allowed extension. If you unpack Linux kernel tarballs in your Music folder, this is for you! (Remember Tracker isn’t designed to index source code). We also dropped a buggy and pointless codepath that tried and mostly failed to extract metadata from random image/* type files using GStreamer’s Discoverer API.
Tracker Extract is designed for robustness but it also needs to report errors. If extraction of foo.flac fails it may indicate a bug in Tracker, or in GStreamer, or libflac, or (more likely) the file is corrupt or mis-labelled. In Tracker Miners 3 we have improved how extraction errors are reported — instead of using the journal, we log errors to disk (at ~/.cache/tracker3/files/errors/). This prevents any ‘spamming’ of the journal when many errors are detected. You can check for errors by running tracker3 status. Perhaps Nautilus could make these errors visible in future too.
Since Tracker Miners 3.0.0 was released, distro beta testers found twoissues that could cause high CPU usage. These are fixed in the 3.0.1 release. If you see any issues with Tracker Miners 3.0.1, please report them on GitLab!
Here I also want to mention Benjamin’s excellent work to improve resource management for system services. Tracker Miner FS tries to avoid heavy resource use but filesystem IO is infinitely complicated and we cannot defend against every possible situation. Strange filesystems or bugs in dependencies can cause high CPU or IO consumption. If the kernel’s scheduler is not smart, it may focus on these tasks at the expense of the important shell and app processes, leaving the desktop effectively locked. Benjamin’s work lets the kernel know to prioritize a responsive desktop above any system services like Tracker Miner FS. Mac OS X could do this since 2013.
Whatever this decade brings, it should be free from desktop lockups!
Standards
The 2.x to 3.x transition was difficult partly because Tracker missed some big pieces of the SPARQL standard. Implementing a 3.x-to-2.x translation layer was out of the question — we had no motivation to re-implement the quirks of 2.x just so apps could avoid porting to 3.x.
I don’t see another major version break in Tracker’s near future, but we are now prepared. Tracker implements almost all of the SPARQL 1.1 standard.
SPARQL is not without its drawbacks — more on that in a future article — but aside from a few simple C and DBus interfaces, all of Tracker’s functionality is accessible through this W3C standard query language. Better to reuse standards than to make our own.
…and more
We have a new website, improved documentation. The tracker3 commandline tool saw loads of cleanups and improvements. Files are automatically re-processed when the relevant tracker-extract module changes — a ten year old feature request. Debugging is nicer as a keyword-enabled TRACKER_DEBUG variable replaces the old TRACKER_VERBOSITY. Deprecated APIs and dependencies are gone, including the venerable intltool. The core and Nepomuk ontologies are slimmed down and better organised. We measure test coverage, and test coverage is higher than ever. We enabled Coverity static analysis too which has found some obscure bugs. I’m no doubt forgetting some things.
A few of these changes impact everyone, but mostly the improvements benefit power users, app developers, and ourselves as maintainers. It’s crucial that a volunteer-driven project like Tracker is easy and fun to maintain, otherwise it can only fail. I think we have paved the way for a bright future.
Come back next week to find out more about the background and future of Tracker.
This is part 1 of a series. Come back next week to find out more about the changes in Tracker 3.0.
It’s too early to say “Job done”. But we’ve passed the biggest milestone on the project we announced last year: version 3.0 of Tracker is released and the rollout has begun!
We wanted to port all the core GNOME apps in a single release, and we almost achieved this ambitious goal. Nautilus, Boxes, Music, Rygel and Totem all now use Tracker 3. Photos will require 2.x until the next release. Outside of GNOME core, some apps are ported and some are not, so we are currently in a transitional period.
The important thing is only Tracker Miner FS 3 needs to run by default. Tracker Miner FS is the filesystem indexer which allows apps to do instant search and content discovery.
Since Photos 3.38 still uses Tracker 2.x we have modified it to start Tracker Miner FS 2 along with the app. This means the filesystem index in the central Tracker 2 database is kept up-to-date while Photos is running. This will increase resource usage, but only while you are using Photos. Other apps which are not yet ported may want to use the same method while they finish porting to Tracker 3 — see Photos merge request 142 to see how it’s done.
Flatpak apps can safely use Tracker Miner FS 3 on the host, via Tracker’s new portal which guards access to your data based on the type of content. It’s up to the app developer whether they use the system Tracker Miner service, or whether they run another instance inside the sandbox. There are upsides and downsides to both approaches.
We all owe thanks to Carlos for his huge effort re-thinking and re-implementing the core of Tracker. We should also thank Red Hat for sponsoring some of this work.
I also want to thank all the maintainers who collaborated with us. Marinus and Jean were early adopters in GNOME Music and gave valuable feedback including coming to the regular meetings, along with Jens who also ported Rygel early in the cycle. Bastien dug into reviewing the tracker3 grilo plugin, and made some big improvements for building Tracker Miners inside a Flatpak. In Nautilus, Ondrej and Antonio did some heroic last minute review of my branch and together we reworked the Starred Files feature to fix somelongstandingissues.
The new GNOME VM images were really useful for testing and catching issues early. The chat room is very responsive and friendly, Abderrahim, Jordan and Valentin all helped me a lot to get a working VM with Tracker 3.
GNOME’s release team were also responsive and helpful, right up to the last minute freeze break request which was crucial to avoiding a “Tracker Miner FS 2 and 3 running in parallel” scenario.
Thanks also to GNOME’s translation teams for keeping up with all the string changes in the CLI tool, and to distro packagers who are now working to make Tracker 3 available to you.
Coming soon to your distro.
It takes time for a new GNOME release to reach users, because most distros have their own testing phase.
We can use Repology to see where Tracker 3 is available. Note that some distros package it in a new tracker3 package while others update the existing tracker package.
Let’s see both:
Coming up…
I have a lot more to write about following the Tracker 3.0 release. I’ll be publishing a series of blog posts over the next month. Make sure you subscribe to my blog or to Planet GNOME to see them all!
GNOME’s conference is online this year, for obvious reasons. I spent the last 3 month teaching online classes so hopefully I’m prepared! I’m sad that there’s no Euro-trip this year and we can’t hang out in the pub, but nice that we’re saving hundreds of plane journeys.
There will be two talks related to Tracker: Carlos and I speaking about Tracker 3 (Friday 23rd July, 16.45 UTC), and myself on how to deal with challanges of working on GNOME’s session-wide daemons (Thursday 22nd July, 16.45 UTC). There are plenty of other fascinating talks, including inevitably one scheduled the same time as ours which you should, of course, watch as a replay during the break 🙂
Self-contained Tracker 3 apps
Let’s go back one year. The plan for Tracker 3 emerged when I spoke to Carlos Garnacho at GUADEC 2019 in Thessaloniki probably over a Freddo coffee like this one…
We had lots of improvements we want to make, but we knew we were at the limit of what we could to Tracker while keeping compatibility with the 10+ year old API. Changing a system service isn’t easy though (hence the talk). I’m a fan of the ‘Flatpak model’ of app deployment, and one benefit is that it can allow the latest apps to run on older LTS distributions. But there’s no magic there – this only works if the system and session-wide services follow strict compatibility rules.
Tracker 3.0 adds important features for apps and users, but these changes require apps to use a new D-Bus API which won’t be available on older operating systems such as Ubuntu 20.04.
We’re considering various ways around this, and one that I prototyped recently is to bundle Tracker3 inside the sandbox. The downside is that some folders will be double indexed on systems where we can’t use the host’s Tracker, but the upside is the app actually works on all systems.
I created a branch of gnome-music demoing this approach. GNOME’s CI is so cool now that you can just go to that page, click ‘View exposed artifact’, then download and install a Flatpak bundle of gnome-music using Tracker 3! If you do, please comment on the MR about whether it works for you 🙂 Next on my list is GNOME Photos, but this is more complex for various reasons.
Blocklists and Allowlists
Black people don't care if u stop saying "master bedroom" or if u remove problematic shows from decades ago from hulu, Black people want an end to police brutality and institutionalized racism. everything else is useless pandering
The world needs major changes to stamp out racism, and renaming variables in code isn’t a major change. That said, the terms ‘blacklist’ and ‘whitelist’ rely on and reinforce an association of ‘black bad, white good’. I’m happy to see a trend to replace these terms including Google, Linux, the IETF, and more.
It was simple to switch Tracker 3 to use the more accurate terms ‘blocklist’ and ‘allowlist’. I also learned something about stable releases — I merged a change to the 2.3 branch, but I didn’t realise that we consider the stable branch to be in ‘string freeze’ forever. (It’s obvious in hindsight 🙂 We’ve now reverted that but a few translation teams already updated their translations, so to the Spanish, Brazilian Portuguese and Romanian translators – sorry for creating extra work for you!
Acknowledging merge requests
I’ve noticed while working on app porting that some GNOME projects are quite unresponsive to merge requests. I’ve been volunteering my time as a GNOME contributor for longer than I want to remember, but it still impacts my motivation if I send a merge request and nobody comments. Part of the fun of contributing GNOME is being part of such an huge and talented community. How many potential contributors have we lost simply by ignoring their contributions?
This started me thinking about how to improve the situation. Being a GNOME maintainer is not easy and is in most cases unpaid, so it’s not constructive to simply complain about the situation. Better if we can mobilise people with free time to look at whatever uncommented merge requests need attention! In many cases you can give useful feedback even if you don’t know the details of the project in question – if there’s a problem then it doesn’t need a maintainer to raise it.
So my idea, which I intend to raise somewhere other than my blog when I have the time, is we could have a bot that posts to discourse.gnome.org every Friday with a list of merge requests that are over a week old and haven’t received any comments. If you’re bored on a Friday afternoon or during the weekend you’ll be able to pick a merge request from the list and give some feedback to the contributor – a simple “Thanks for the patch, it looks fine to me” is better than silence.
Let me know what you think of the idea! Can you think of a better way to make sure we have speedy responses to merge requests?
Lots of effort is going into Tracker at the moment. I was waiting for a convenient time to blog about it all, but there isn’t a convenient moment on a project like this, just lots of interesting tasks all blocked on different things.
App porting
With the API changes mostly nailed down, our focus moved to making initial Tracker 3 ports of the libraries and apps that use Tracker. This is a crucial step to prove that the new design works as we expect, and has helped us to find and fix loads of rough edges. We want to work with the maintainers of each app to finish off these ports.
If you want to help, or just follow along with the app porting, the process is being tracked in this GNOME Initiatives issue.
The biggest success story so far is GNOME Music. The maintainers Jean and Marinus are regular collaborators in #tracker and in our video meetings, and we’ve already got a (mostly) working port to Tracker 3. You can download a Flatpak build from that merge request, but note that it requires tracker-miners 3.0 installed on your host.
We’re hoping we can work around the host dependency in most cases, but I got excited and made unofficial Fedora packages of Tracker 3 which allowed me to try it out on my laptop.
We are also happy that GTK can be built against Tracker 3 already, and excited for the work in progress on Rygel. At the time of writing, the other apps with Tracker 3 work in progress Boxes, Files, Notes, Photos, Videos. Some of these use the new tracker3 Grilo plugin which we hope a Grilo maintainer will be able to review and merge soon. All help with finishing these branches and the remaining apps will be very welcome.
Release strategy
We have been putting thought into how to release Tracker 3. We need collaboration on two sides: from app maintainers who we need to volunteer their time and energy to review, test and merge the Tracker 3 changes in their apps, and from distros who we need to volunteer their time to package the new version and release it.
We have some tricky puzzles to solve, the main one being how an app might switch to Tracker 3 without breaking on Ubuntu 20.04 and other distros that are unlikely to include Tracker 3, but are likely to host the latest Flatpak apps.
We are hoping to find a path forward that satisfies everyone, again, you can follow the discussion in Initiative issue #17.
As you can see, we are volunteering a lot of our time at the moment to make sure this complicated project is a success.
Data exporting
We made it more convenient to export data from Tracker databases, with the tracker export command. It’s nice to have a quick way to see exactly what is stored there. This feature will also be crucial for exporting app data such as photo albums and starred files from the centralized Tracker 2 database.
Hardware testing with umockdev
The removable device support in Tracker goes largely untested, because you need to actually plug and unplug a real USB to exercise it. As always, for a volunteer driven project like Tracker it’s vital that testing the code is as easy as possible.
I recently discovered umockdev and decided to give it a spin. I started with the power management code because it’s super simple – on low battery notication, we stop the indexer. I’m happy with the test code but unfortunately it fails on GNOME’s CI runners with an error from umockdev:
sendmsg_one: cannot connect to client's event socket: Permission denied
I’m not sure when I’ll be motived to dig into why this fails, since the problem only reproduces on the CI runners, so if anyone has a pointer on what’s wrong then please comment on the MR.
The pandemic also means I’m likely to be spending the whole summer here in Galicia which can hardly be seen as bad luck. Here’s a photo of a beautiful spot I discovered recently about 30km from where I live:
Next steps
Carlos is working on some final API tweaks before we make another Tracker 2.99 beta release, after which the API should be fully stable. The Flatpak portal is also nearly ready.
We hope to see progress with app ports. This depends more and more on when app developers can volunteer their time to collaborate with us. Progress in the next few weeks will decide whether we target GNOME 3.38 (September 2020) or GNOME 3.40 (March 2021) for switching everything over to Tracker 3.
Unlike GTK 4, I can’t show any cool screenshots. I do have some ideas about how to demonstrate the improvements over Tracker 2, however … watch this space!
As always, we are available on IRC/Matrix in #tracker and you are welcome to join our online meetings.
It’s cool storing stuff in a database, but what if you shared the database schema so other tools can work with the data? That’s the basic idea of Linked Data which Tracker tries to follow when indexing your content.
In a closed music database, you might see a “Music” table with a “name” column. What does that mean? Is it the name of a song, an artist, an album, … ? You will have to do some digging to find out.
When Tracker indexes your music, it will create a table called nmm:MusicAlbum. What does that mean? You can click the link to find out, because the database schema is self-documenting. The abbreviation nmm:MusicAlbum expands to a URL, which clearly identifies the type of data being stored.
By formalising the database schema, we create a shared vocabulary for talking about the data. This is very powerful – have you seen GMail Highlights, where a button appears in your email inbox to checkin for a flight and such things? These are powered by the https://schema.org/ shared vocabulary. Google don’t manually add support to GMail for each airline in the world. Instead, the airlines embed a https://schema.org/FlightReservation resource in the confirmation email which GMail uses to show the information. The vocabulary is an open standard, so other email providers can use the same data and even propose improvements. Everyone wins!
Recent improvements
Tracker began 5 years before the creation of schema.org, and we use an older vocabulary from a project called Nepomuk. Tracker may now be the only user of the Nepomuk vocabularies, but to avoid a huge porting effort we have opted to keep using them for 3.0.
Inspired by schema.org documentation, I changed the formatting of Tracker’s schema documentation trying to pack the important information more densely. Compare the 2.x documentation to the 3.x documentation to see what has changed – I think it’s a lot more readable now.
One thing you will notice if you followed the nmm:MusicAlbum link above is that the contents of the documentation still requires some improvement. I hope to see incremental improvements here; if you think you can make it better, please send us a merge request !
CLI documentation
We maintain documentation for the tracker CLI tool in the form of man pages. These were a bit neglected. We now publish the man pages online making it easier to read them and harder to forget they exist.
There is a well-written and quite outdated set of documentation at https://wiki.gnome.org/Projects/Tracker. It’s mostly aimed at setting up Tracker on systems where it doesn’t come ready-integrated – which is a use case we don’t really want to support. I’m a bit stuck as I don’t want to delete what is quite good content, but I also don’t want to maintain documention for things that nobody should need to do…
Documentation hosting
This is a periodic reminder that the library-web script that manages developer.gnome.org needs a major reworking, such as the one proposed here. All the Tracker documentation on http://developer.gnome.org/ is years out of date, because we switched to Meson which requires us to do extra effort on each release to post the documentation. Much kudos is awaiting the people who can resolve this.
Stay tuned
Work is proceeding nicely on Tracker 3.0 and we hope to have the first beta release ready within the next couple of weeks. At that point, there will be opportunities to help with testing app ports and making sure performance is good – I will keep you posted here!
This article has been updated to correct a misunderstanding I had about the CONSTRAINT feature. Apps will not need to explicitly add this to their queries, it will be added implicitly by the xdg-tracker-portal process..
Lots has happened in the 2 months since my last post, most notably the global coronavirus pandemic … in Spain we’re in week 3 of quarantine lockdown already and noone knows when it is going to end.
Let’s take our mind off the pandemic and talk about Tracker 3.0. At the start of the year Carlos worked on some key API changes which are now merged. It’s a good opportunity to recap what’s really changing in the new version.
I made the developer documentation for Tracker 3.0 available online. Thanks to GitLab, this can be updated every time we merge a change in Git. The documentation a work in progress and we appreciate if you can help us to improve it.
The documentation contains a migration guide, but let’s have a broader look at some common use cases.
Tracker 3.0 is still in development and things may change! We very much welcome feedback from app developers who are going to use this API.
Browsing and searching
The big news in Tracker 3.0 is decentralization. Each app can now manage its own private database! There’s no single “Tracker store” any longer.
Tracker 3.0 will index content from the filesystem to facilitate searching and browsing, as it does now. The filesystem miner will keep this in its own database, and Flatpak apps will access this database through a portal (currently in development).
Apps access this data using a TrackerSparqlConnection just like now, but when we create the connection we need to specify that we want to connect to the filesystem miner’s database.
Here’s a Python example of listing all the music files in the user’s ~/Music directory:
from gi.repository import Tracker
conn = Tracker.SparqlConnection.bus_new(
"org.freedesktop.Tracker3.Miner.Files", None, None)
cursor = conn.query(
'SELECT ?url { ?r a nmm:MusicPiece ; nie:url ?url }')
print("Found music files:\n")
while cursor.next():
print(cursor.get_string()[0][0])
Running a full text search will be similar. Here’s how you’d look for “bananas” in every file in the users ~/Documents folder:
If you are running inside a Flatpak sandbox then there will be a portal between you and the org.freedesktop.Tracker3.Miner.Files database. The read-only /.flatpak-info file inside the sandbox, which is created when building the Flatpak, will declare what graphs your app can access. The xdg-tracker-portal will add that information into the SPARQL query, using a Tracker-specific syntax like this: CONSTRAINT GRAPH , and the database will enforce the constraint ensuring that your app really does only see the graphs that it’s requested access to.
Storing your own data
Tracker can be used as a data store by applications. One principle behind the design of Tracker 1.x was that by using a centralized store and a common vocabulary, different apps could easily share data. For example, when you create an album in GNOME Photos, it’s stored in the Tracker database using the standard nfo:DataContainer class. Any other app, perhaps a file manager, or a photos app from a different platform, can show and edit albums stored in this way without having to know specifics about GNOME Photos. Playlists in GNOME Music and starred files in Nautilus are also stored this way.
This approach had some downsides. Having all data in a single database creates a single point of failure. It’s hard to backup the valuable user data without backing up the search and indexing data too – but since the index can be recreated from the filesystem, it’s a waste of resources to include that in a backup. Apps were also forced to share a single database schema which was maintained in the tracker.git repository.
Tracker 3.0, each app creates a private database for storing its own data. It can use the ontology (database schema) from Tracker, or it can provide its own version. Here’s how a photos app written in Python could store photo albums:
Now let’s insert a photo into this album. Remember that the user’s photos are indexed by the filesystem miner. We can use the SERVICE statement to connect the filesystem miner’s database to our app’s private database, like this:
Notice again that the app has to request permission to access the Photos graph. If our example app is running in Flatpak, this will require a special permission.
It’s still possible for one app to share data with another, but it will require coordination at the app level. Using the example of photo albums, GNOME Photos can opt to make its database available to other apps. If a different app wants to see the user’s photo albums, they’ll need to connect to the org.gnome.Photos database over D-Bus. As usual, Flatpak apps would need permission to do this.
Is it a good time to port my app to Tracker 3.0?
It’s a good time to start porting your app. You will definitely be able to help us with testing and stabilising the library and the documentation if you start now.
Some functionality is no longer exposed in C libraries, due to the privitization of libtracker-control and libtracker-miner. As far as we know libtracker-miner is unused outside Tracker, but some apps are currenly using libtracker-control to display status updates for the Tracker daemons and trigger indexing of removable devices. We have an open issue about improving the story for on-demand removable device indexing. For status monitoring you may use the underlying DBus signals, and I’m also hoping to make these more useful.
Ideally I’d like to add a new helper library for Tracker 3.0 which would conveniently wrap the high level features that apps use. My volunteer time is limited though. I can share ideas for this if you are looking for a way to contribute!
What about a hackfest?
At some point we need to finish the Tracker 3.0 work and make sure that apps that use Tracker are all ported and working. The best case is that we do this in time for the upcoming GNOME 3.38 release. We discussed about a hackfest some point between now and GNOME 3.38 to make sure things are settled; it now may be that an in-person hackfest won’t be feasible in light of the Coronavirus pandemic but a series of online meetings would be a good alternative. We can only wait, and see!
Tracker’s database is now up to date with the latest SPARQL 1.1 standards, including the magical SERVICE statement that lets you combine results from multiple databases in a single query. Now we’re converting the database from a service into a library, and turning the previously monolithic architecture into something more flexible.
Carlos has already done most of this work and the code is pushed as #172 (tracker.git) and #136 (tracker-miners.git). At times it feels like we’re carving a big block of stone into a sculpture — just look at the diffstats:
Read merge request #172 for full details, but the highlights are that there’s no more tracker-store daemon, and the libtracker-sparql library which was previously only used for querying and inserting data can now be used to create and manage your own database. You can keep the database private, or you can expose it over D-Bus.
The code in tracker.git is now only about managing data. We may rename it to tracker-sparql in due course, or even to SPARQLite if this is okayed by the developers of SQLite. There’s perhaps a niche for a desktop-scale database that supports SPARQL queries, and it’s a niche that Tracker’s database fits in nicely.
All the code related to desktop indexing and search is now in tracker-miners.git. The tracker-miner-fs daemon will maintain the index in its own database, which you’ll be able to query by connecting over D-Bus just like you used to connect to tracker-store in Tracker 2.0. However, apps running inside Flatpak will not be able to talk directly to the tracker-miner-fs daemon — communication will go through a new portal that Carlos is currently working on, allowing us to implement per-app access controls to your data for the first time.
We are still pending a Tracker 2.3.2 bugfix release too! This month Victor Gal solved an issue that was causing photo geolocation metadata to be ignored. Rasmus Thomsen also added Alpine Linux to our CI, and the GNOME translation teams have been hard at work too.
If you want to help out by testing, developing, documenting Tracker – get in touch on GNOME Discourse (use the ‘tracker’ tag) or irc.gnome.org #tracker.
Rasmus Thomsen has been testing on Alpine Linux, fixing one issue and finding several more. Alpine Linux uses musl libc instead of the more common GNU libc, which triggers bugs that we don’tusuallysee. Finding and fixing these issues could be a great learning experience for someone who wants to dig deep into the platform!
There’s an ongoing issue reported by many Ubuntu users which seems to be due to SQLite database corruption. SQLite is rather a black box to me, so I don’t know how or when we might get to the bottom of why this corruption is happening.
Ubuntu CI
We now test each commit on Ubuntu as well as Fedora. This a nice step forwards. It’s also triggering more intermittentfailures in the CI — we’ve made huge progress in the last few years on bringing the CI up from zero, but there are some latent issues like these which we need to get rid of.
Tracker 3.0
Carlos has done more architectural work in the ‘master’ branch, working towards having a generic SPARQL store in tracker.git, and all GNOME/desktop/filesystem related code in tracker-miners.git.
As part of this, the tracker CLI tool is now split between tracker.git and tracker-miners.git (MR1, MR2).
We also moved the libtracker-control and libtracker-miner libraries into tracker-miners.git, and made the libtracker-control API private. As far as I know, the libtracker-control library is only being used by GNOME Photos to manage indexing of removable devices. We want to keep track of which apps need porting to 3.0, so please let me know if this is going to affect anything else.
New website
Tracker is famous enough that it merits a real website, not just an outdated set of wiki pages. So I made a real Tracker website, aiming to collect links to relevant user and developer documentation and to have a minimal overview and FAQ section. We can build and deploy this straight from the tracker.git repo, so whereas the wiki is easily forgotten, the new website lives in the same repo as the sourcecode. The next step will be to merge this and then tidy up most of the old wiki pages
I’ve continued looking at the developer experience of Tracker. Recently we modernized the README.md file (as several GNOME projects have done recently). I want the README to document a simple “build and test Tracker from git” workflow, and that led into work making it simpler to run Tracker from the build tree, and also a bunch of improvements to the test suite.
The design of Tracker has always meant that it’s a pain in the ass to build and test, because to do anything useful you need to have 3 different daemons running and talking to each other over D-Bus, reading and writing data in the same location, and communicating with the CLI or an app. We had a method for running Tracker from the build tree for use by automated tests, whose code was duplicated in tracker.git and tracker-miners.git, and then we had a separate script for developers to test things manually, but you still had to install Tracker to use that one. It was a bit of a mess.
The first thing I fixed was the code duplication. Now we have a Python module named trackertestutils. We install it, so we don’t need to duplicate code between tracker.git and tracker-miners.git any more. Thanks to Marco Trevisan we also install a pkgconfig file.
Then I added a ./run-uninstalled script to tracker-miners.git. The improvement in developer experience I think is huge. Now you can do this to try out the latest Tracker code:
git clone tracker-miners.git
cd tracker-miners && mkdir build && cd build
meson .. && ninja
./run-uninstalled --wait-for-miner=Files --wait-for-miner=Extract -- tracker index --file ~/Documents
./run-uninstalled -- tracker search "Hello"
The script is a small wrapper around trackertestutils, which takes care of spawning a private D-Bus daemon, collecting and filtering logs, and setting up the environment so that the Tracker cache is written to `/tmp/tracker-data`. (At the time of writing, there are some bug still and ./run-installed actually still requires you to install Tracker first.)
I also improved logging for Tracker’s functional-test suite. Since a year ago we’ve been running these tests in CI, but there have been some intermittent failures, which were hard to debug because log output from the tests was very messy. When you run a private D-Bus session, all kinds of daemons spawn and dump stuff to stdout. Now we set G_MESSAGE_PREFIXED in the environment, so the test harness can separate the messages that come from Tracker processes. It’s already allowed me to track down some of these annoying intermittent failures, and to increase the default log verbosity in CI.
Another neat thing about installing trackertestutils is that downstream projects can use it too. Rishi mentioned at GUADEC that gnome-photos has a test which starts the photos app and ends up displaying the actual photo collection of the user who is running the test. Automated tests should really be isolated from the real user data. And using trackertestutils, it’s now simple to do that: here’s a proof of concept for gnome-photos.
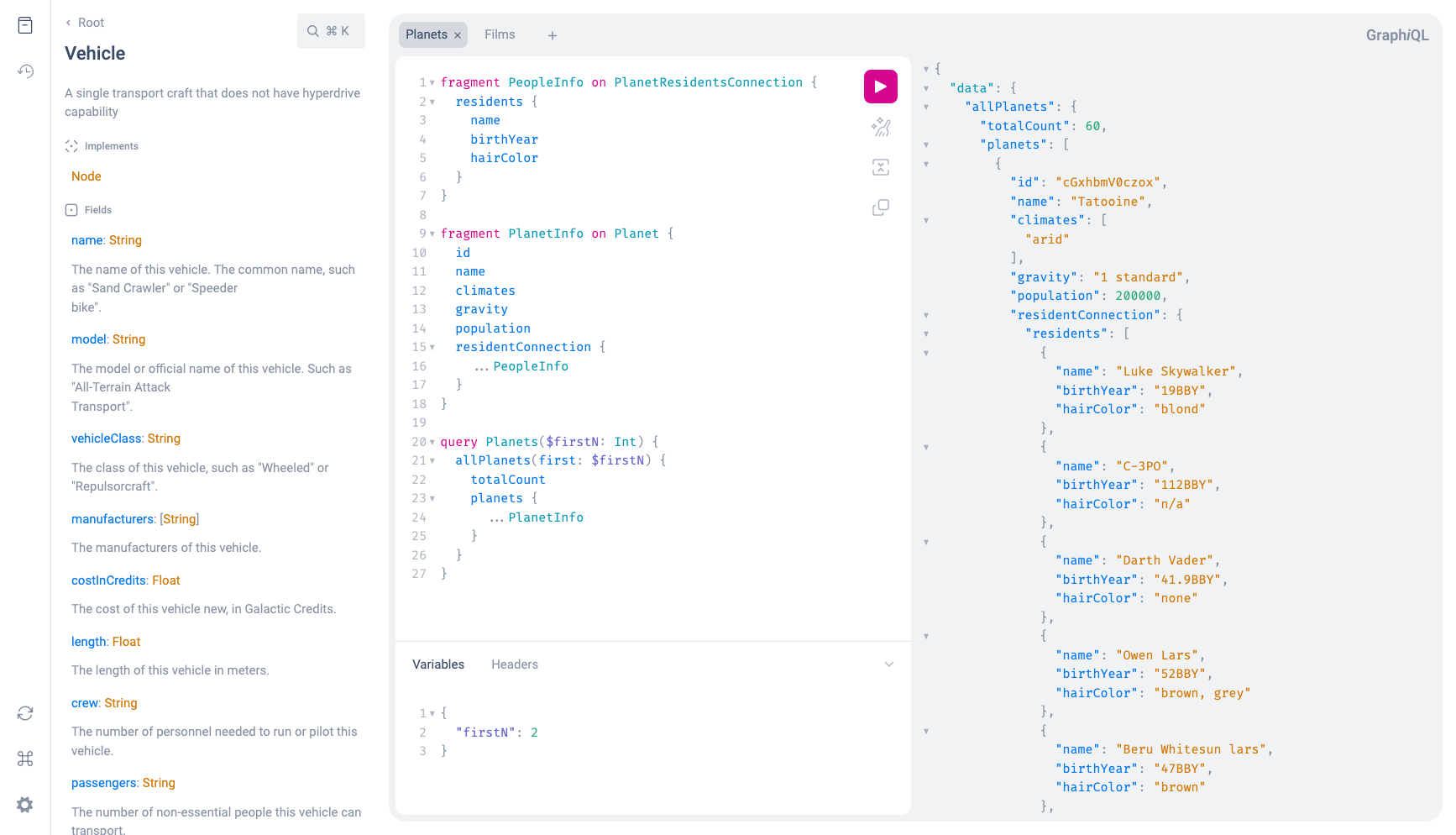

































{kind=link}
{kind=link}