GNOME 46 just released, and with it comes TinySPARQL 3.7 (aka Tracker SPARQL) and Tracker Miners 3.7. Here’s what I’ve been involved with this month in those projects.
Google Summer of Code
It wasn’t my intention to prepare another internship before the last one was even finished. It seems that in GNOME we have fewer projects and mentors than ever – only eight ideas this year, compared to fourteen confirmed projects back in 2020. So I proposed an idea for TinySPARQL, and here we are.
The idea, in brief: I’ve been working a bit with GraphQL recently, which doesn’t live up to the hype, but does have nice query frontends such as GraphQL Playground and graphiql that let you develop and test queries in realtime. This is a screenshot of graphiql:
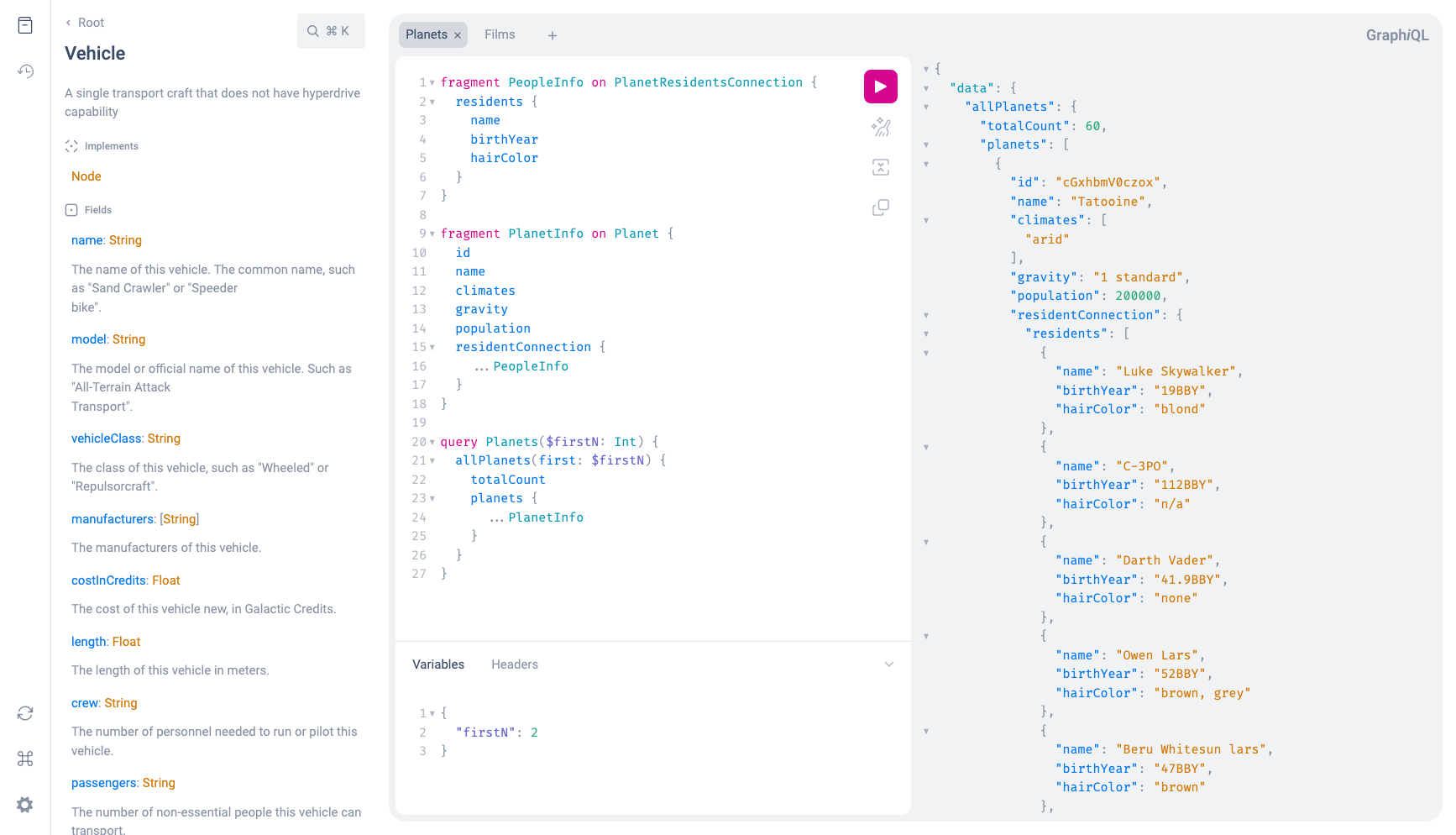
In TinySPARQL, we have a commandline tool tracker3 sparql which can run queries and print the results. This is handy for developing testing queries independently of the app logic, but it’s only useful if you’re already something a SPARQL expert.
What if TinySPARQL had a web interface similar to the GraphQL Playground?
Besides running queries and showing the output, this could have example queries, resource browsing, as-you-type error checks, integrated documentation, and more fun things listed in this issue. My hope is this would encourage more folk to play around with the data running interesting queries and would help to visualize what you can do with a detailed metadata index for your local content. I think a lot of people see Tracker Miner FS as a black box that does basic string matching, and not the flexible database that it actually is.
Lots of schools teach HTML and JavaScript so this project seems like a great opportunity for an intern to take ownership of and show their skills. Applications are open until 2nd April, and we’ll be running a couple of online meetups later this week (Thursday 21st and/or Friday 22nd March) to help you create a good application. Join the #tracker:gnome.org Matrix room if you’re interested.
By the way, it’s only recently been possible to separate your queries from the rest of your app’s code. I wrote about this here: Standalone SPARQL Queries. The TrackerSparqlStatement class is flexible and fun and you can read your SPARQL statements straight from a GResource file. If you used libtracker-sparql around 1.x you’ll remember a horrible thing named TrackerSparqlBuilder – the query developer experience has come a long way since then.
New security features
There are some new features this cycle thanks to hard work by Carlos. I’ll let him write up the fun parts. One part that’s not much fun, is the increased security protections for tracker-extract. The background here is that tracker-extract uses many different media parsing libraries, and if any one of those libraries shipped by your distro contains a vulnerability, that could potentially be exploited by getting you to download a malicious file which would then be processed by tracker-extract.
We have no evidence that anyone’s ever actually done this. But there was a writeup on how it could happen recently using a vulnerability in a library named libcue which nobody is maintaining, including a clever bypass of the existing SECCOMP protection. Carlos did a writeup of this on his blog: On CVE-2023-43641.
With Tracker Miners 3.7, Carlos extended the existing SECCOMP sandbox to cover the entire extractor process rather than just the processing thread, which prevents that theoretical line of attack. And, he added an additional layer of sandboxing using a new kernel API called Landlock, which lets a process block itself from accessing any files except those it specifically needs.
From my perspective it’s rather draining to help maintain the sandboxing. When it works, nobody notices. When the sandboxing causes issues, we hear about it straight away. And there are plenty of issues! Even the build-time configuration for Landlock seems to need hours of debate.
SECCOMP works by denying access to any kernel APIs except those legitimately needed by the extractor process and the libraries it uses. Linux has 450+ syscalls and counting, and we maintain an explicit allowlist. Any change to GLibc, GIO, GStreamer or any media parsing library may then change what syscall gets used. If an unexpected syscall is called the tracker-extract process is killed with SIGSYS, which gets reported as a crash in just the same way as segfaults caused by programming errors.
It’s draining to support something that can break randomly by things that are out of our control. What else can we do though?
What’s next?
It might seem like openQA testing and desktop search are unrelated, but there is a clear connection.
Making reproducible integration tests for a search engine is a very hard problem. Back last decade I worked on the project’s Gitlab CI setup and “functional tests”. These tests live in the tracker-miners.git source tree, and run the real the crawler and extractor, testing that we can create a file named hello.txt, wait for it to be indexed and search for its contents. Quite a step forwards from unreproducible “works on my machine” testing that came before, but not representative of real use cases.
Real GNOME users do not have a single file in their home dir named hello.txt. Rather they have GBs or TBs of content to be indexed, and they have expectations about what constitutes the “best match” for a given search term.
I’m not interested in working to solve this kind of thing until we can build regression tests so that things don’t just work, but keep working in the long term. Hence, the work-in-progress gnome_search test for openQA, and the example-desktop-content repo. This is at the “working prototype” stage, and is now ready for some deeper thinking about what specific scenarios we want to test.
Some other things that may or may not happen next cycle in desktop search, depending on whether people care to help push them forwards:
- beginning the rename: this won’t happen all at once, but we want to start calling the database TinySPARQL, and the indexer something else, still to be decided. (Ideas welcome!)
- a ‘limiter’ to detect when a directory contains so much content that the indexer would burn significant CPU and IO resource trying to index everything up front (which requires corresponding UI changes so that there’s a way to “opt in” to indexing such locations on demand)
- indexing the whole $HOME directory (which I personally don’t want to land without the ‘limiter’ in place, but let’s see)
One thing is certain, next month things are certainly going to slow down for me… I’m holiday for two full weeks over Easter, spring is coming and I plan to spend most of my time relaxing in a hammock. Hopefully we’ve sowed a lot of seeds this month which will soon turn into flowers.

Aww, TinySPARQL could’ve been called “Sparqlelight” 😦
Yes! We actually wanted to call it Sparqlite but couldn’t get permission from the SQLite devs
integration with workbench might be ba good idea