In which I meet QA testers, bang my head against the GNOME OS initial setup process, and travel overland from Scotland to Spain in 48 hours.
Linux QA meetup
Several companies and communities work on QA testing for Linux distros, and we mostly don’t talk to each other. GUADEC 2023 was a rare occasion where several of us were physically collocated for a short time, and a few folk proposed a “GNOME + openQA hackfest” to try and consolidate what we’re all working on.
Over time, we realized ongoing lines of communication are more useful than an expensive one-off meetup, and the idea turned into a recurring monthly call. This month we finally held the first call. In terms of connecting different teams it was a success – we had folk from Canonical/Ubuntu, Codethink, Debian, GNOME, Red Hat/Fedora and SUSE, and there are some additional people already interested in the next one. Everyone who attended this round is using openQA and we will to use the openqa:opensuse.org chat to organise future events – but the call is not specific to openQA, nor to GNOME: anything Linux-related and QA-related is in scope.
If you want to be involved in the next one, make sure you’re in the openQA chat room, or follow this thread on GNOME Discourse. The schedule is documented here and the next call should be 08:00UTC on Thursday 2nd May.
GNOME OS tests
On the topic of QA, the testsuite for GNOME OS is feeling pretty unloved at the moment. Tests still don’t pass reliably and haven’t done for months. Besides the existing issue with initial setup where GNOME Shell doesn’t start, there is a new regression that breaks the systemd user session and causes missing sound devices. Investigating these issues is a slow and boring process which you can read about in great detail on the linked issues.
Fun fact: most of GNOME OS works fine without a systemd user session – there is still a D-Bus session bus after all; systemd user sessions are quite new and we still (mostly) support non-systemd setups.
One thing is clear, we still need a lot of work on tooling and docs around GNOME OS and the tests, if we hope to get more people involved. I’m trying my best in the odd hours I have available, greatly helped by Valentin David and other folk in the #GNOME OS channel, but it still feels like wading through treacle.
We particularly could do with documentation on how the early boot and initial setup process is intended to work – its very hard to visualize just from looking at systemd unit files. Or maybe systemd itself can generate a graph of what should be happening.
Magic in the ssam_openqa tool
Debugging OS boot failures isn’t my favourite thing. I just want reliable tests. Writing support tooling in Rust is fun though, and it feels like magic to be able to control and debug VMs from a simple CLI tool, and play with them over VNC while the test suite runs.
Using a VNC connection to run shell commands is annoying at times: it’s a terminal in a desktop in a VNC viewer, with plenty of rendering glitches, and no copy/paste integration with the host. I recently noticed that while openQA tests are running, a virtio terminal is exposed on the host as a pair of in/out FIFOs, and you can control this terminal using cat and echo. This feels like actual magic.
I added a new option to ssam_openqa, available whenever the test runner is paused, to open a terminal connection to this virtio console, and now I can debug directly from the terminal on my host. I learned a few things about line buffering and terminal control codes along the way. (I didn’t get ANSI control codes like cursor movement to work, yet – not sure if my code is sending them wrong, or some TERM config is needed on the VM side. – but with backspace, tab and enter working it’s already fairly usable).
Here’s a quick demo of the feature:
Available in the 1.2.0-rc1 release. Happy debugging!
Cross country travel
Most of this month I was on holiday. If you’re a fan of overland travel, how about this: Aberdeen to Santiago in 48 hours; via night train to Crewe, camper van to Plymouth, ferry to Santander and then more driving across to Galicia. A fun trip, although I got pretty seasick on the boat until I’d had a good nights sleep. (This wasn’t a particularly low-carbon trip though despite going overland, as the train, ferry and van are all powered by big diesel engines.)
And now back to regular work – “Moving files from one machine to another using Python and YAML”, etc.
Looking back at this month its been very busy indeed. In fact, so busy that I’m going to split this status update into two parts.
Possibly this is the month where I worked the whole time yet did almost no actual software development. I guess it’s part of getting old that you spend more time organising people and sharing knowledge than actually making new things yourself. But I did still manage one hack I’m very proud of, which I go into below.
GNOME OS & openQA testing
This month we wrapped up the Outreachy internship on the GNOME OS end-to-end tests. I published a writeup here on the Codethink blog. You can also read first hand from Dorothy and Tanju. We had a nice end-of-internship party on meet.gnome.org last week, and we are trying to arrange US visas & travel sponsorship so we can all meet up at GUADEC in Denver this summer.
There are still a few loose ends from the internship. Firstly, if you need people for Linux QA testing work, or anything else, please contact Dorothy and Tanju who are both now looking for jobs, remote or otherwise.
Secondly, the GNOME OS openQA tests currently fail about 50% of the time, so they’re not very useful. This is due to a race condition that causes the initial setup process to fail so the machine doesn’t finish booting.
Its the sort of problem that takes days rather than hours to diagnose so I haven’t made much of a dent in it so far. The good news is, as announced on Friday, there is now a team from Codethink working full time on GNOME OS, funded partly by the STF grant and partly by Codethink, and this issue is high on the list of priorities to fix.
I’m not directly involved in this work, as I am tied up on a multi-year client project that has nothing to do with open source desktops, but of course I am helping where I can, and hopefully the end-to-end tests will be back on top form soon.
ssam_openqa
If you’ve looked at the GNOME openQA tests you’ll see that I wrote a small CLI tool to drive the openQA test runner and egotistically named it after myself. (The name also makes it clear that it’s not something built or supported by the main openQA project).
I used Rust to write ssam_openqa so its already pretty reliable, but until now it lacked proper integration tests. The blocker was this: openQA is for testing whole operating systems, which are large and slow to deploy. We need to use the real openQA test runner in the ssam_openqa tests, otherwise the tests don’t really prove that things are working, but how can we get a suitably minimal openQA scenario?
During some downtime on my last trip to Manchester I got all the pieces in place. First, a Buildroot project to build a minimal Linux ISO image, with just four components:
The output is 6MB – small enough to commit straight to Git. (By the way, using the default GNU libc the image size increases to 15MB!)
The next step was to make a minimal test suite. This is harder than it sounds because there isn’t documentation on writing openQA test suites “from the ground up”. By copying liberally from the openSUSE tests I got it down to the following pieces:
That’s it – a fully working test that can boot Linux and run commands.
The whole point is we don’t need the openQA web UI in this workflow, so its much more comfortable for commandline-driven development. You can of course run the same testsuite with the web UI when you want.
The final piece for ssam_openqa is some integration tests that trigger these tests and assert they run, and we get suitable messages from the frontend, for now implemented in tests/real.rs.
I’m happy that ssam_openqa is less likely to break now when I hack on it, but i’m actually more excited about having figured out how to make a super minimal openQA test.
The openQA test runner, isotovideo, does something similar in its test suite using TinyCore Linux. I didn’t reuse this; firstly because it uses the Linux framebuffer console instead of virtio terminal, which makes it impossible to read output of the commands in tests; and secondly because it’s got a lot of pieces that I’m not interested in. You can anyway see it here.
Have you used ssam_openqa yet ? Let me know if you have! It’s a fun to be able to interact with and debug an entire GNOME OS VM using this tool, and I have a few more feature ideas to make this even more fun in future.
Some months you work very hard and there is little to show for any of it… so far this is one of those very draining months. I’m looking forward to spring, and spending less time online and at work.
Rather than ranting I want to share a couple of things from elsewhere in the software world to show what we should be aiming towards in the world of GNOME and free operating systems.
Before we even started writing the database, we first wrote a fully-deterministic event-based network simulation that our database could plug into. … if one particular simulation run found a bug in our application logic, we could run it over and over again with the same random seed, and the exact same series of events would happen in the exact same order. That meant that even for the weirdest and rarest bugs, we got infinity “tries” at figuring it out, and could add logging, or do whatever else we needed to do to track it down.
The text is hyperbolic, and for some reason they think it’s ok to work with Palantir, but its an inspiring read.
Secondly, a 15 minute video which you should watch in its entirety, and then consider how the game development world got so far ahead of everyone else. Here’s a link to the video.
This is the world that’s possible for operating systems, if we focus on developer experience and integration testing across the whole OS. And GNOME OS + openQA is where I see some of the most promising work happening right now.
Of course we’re a looooong way from this promised land, despite the progress we’ve made in the last 10+ years. Automated testing of the OS is great, but we don’t always have logs (bug), the image randomly fails to start (bug), the image takes hours to build, we can’t test merge requests (bug), testing takes 15+ minutes to run, etc. Some of these issues seem intractable when occasional volunteer effort is all we have.
Imagine a world where you can develop and live-deploy changes to your phone and your laptop OS, exhaustively test them in CI, step backwards with a debugger when problems arise – this is what we should be building in the tech industry. A few teams are chipping away at this vision – in the Linux world, GNOME Builder and the Fedora Atomic project spring to mind and I’m sure there are more .
Anyway, what happened last month?
Outreachy
This is the final month of the Outreachy internship that I’m running around end-to-end testing of GNOME. We already had some wins, there are now 5 separate testsuites running against GNOME OS, unfortunately rather useless at present due to random startup failures.
I spent a *lot* of time working with Tanju on a way to usefully test GNOME on Mobile. I haven’t been able to follow this effort closely beyond seeing a few demos and old blogs. This week was something of a crash course on what there is. Along the way I got pretty confused about scaling in GNOME Shell – it turns out there’s currently a hardcoded minimum screen size, and upstream Mutter will refuse to scale the display below a certain size. In fact upstream GNOME Shell doesn’t have any of the necessary adaptations for use in a mobile form factor. We really need a “GNOME OS Mobile” VM image – here’s an open issue – it’s unlikely to be done within the last 2 weeks of the current internship, though. The best we can do for now is test the apps on a regular desktop screen, but with the window resized to 360×720 pixels.
On the positive side, hopefully this has been a useful journey for Tanju and Dorothy into the inner workings of GNOME. On a separate note, we submitted a workshop on openQA testing to GUADEC in Denver, and if all goes well with travel sponsorship and US VISA applications, we hope to actually meet in person there in July.
FOSDEM
I went to FOSDEM 2024 and had a great time, it was one of my favourite FOSDEM trips. I managed to avoid the ‘flu – i think wearing a mask on the plane is the secret. From Codethink we were 41 people this year – probably a new record.
My main goal at FOSDEM was to make contact with other openQA users and developers, and we had some success there. Since then i’ve hashed out a wishlist for openQA for GNOME’s use cases, and we’re aiming to set up an open, monthly call where different QA teams can get together and collaborate on a realistic roadmap.
I saw some great talks too, the “Outreachy 1000 Interns” talk and the Fairphone “Sustainable and Longlasting Phones” were particular highlights. I went to the Bytenight event for the first time and and found an incredible 1970’s Wurlitzer transistor organ in the “smoking area” of the HSBXL hackspace, also beating Javi, Bart and Adam at Super Tuxcart several times.
Happy new year everyone! For better or worse we’re now well into the 2020s.
Here are some things I’ve been doing recently.
A post on the GNOME openQA tests: Looking back to 2023 and forwards to 2024. I won’t repeat the post here, go read it and see what I hope to see in 2024 with regards to QA testing.
I’m still mentoring Dorothy and Tanjuate to work on the tests and we’re about at the half way point of the Outreachy internship. Our initial goal was to test GNOME’s accessibility features and this work is nearly done, hopefully we’ll be showing it off this week. Here’s a sneak preview of the new gnome_accessibility testsuite…
These features are sometimes forgotten (at least by me) and I hope this testsuite can serve as a good demo of what accessibility features GNOME has, in addition to guarding against regressions.
It’s hard work to remotely mentor 2 interns on top of 35hrs/wk customer work and various internal work duties, so it’s great that Codethink are covering my time as a mentor, and it also helps that it’s winter and the outside world is hidden behind clouds most of the time. If only it was a face-to-face internship and I could hang out in Uganda or Cameroon for a while. Tanju and Dorothy are great to work with, if you’re looking to hire QA engineers then I can give a good reference for both.
I expect my open source side project for 2024 will still be the GNOME openQA tests, it ties in with a lot of activity around GNOME OS and it feels like we are pushing through useful workflow improvements for all of GNOME. Not that I’ve lost interest in other important stuff like desktop search, music recommendations and playing OpenTTD, but there is only so much you can do with a couple of hours a week.
What else? As usual I’ve been reviewing various speedups and SPARQL improvements from Carlos Garnacho in the Tracker search engine. I’m making plans to go to FOSDEM, so hopefully will see you there (especially if you want to talk about openQA). And I listed out my top 5 albums of 2023 which you should go listen to before doing anything else.
A new discovery of mine for 2023 was the #CrossBorderRail movement. It’s mainly a project of Jon Worth who is investigating all current and former border crossings in the EU by train and bike. His motivation, aside from the fact that I guess he likes to explore, is to highlight obvious issues and improvements which are needed to get more people onto trains and off of short-haul flights. I have some experiences to share in that area myself.
Back in June I made an unambitious commitment to take no more than 10 flights in 2023, which I didn’t actually meet having taken the 11th flight to get back to the UK for Christmas. (I think the climate crisis is built on people making unambitious targets and then failing to meet them anyway). Anyway, I decided to return by train to Santiago.
I have plenty of experience taking unadvisably long overland trips. The apex of this being driving to Mongolia in 2016 and taking the train back from Ulan Ude, Russia to Manchester. By comparison, travelling from North Wales to Galicia seems pretty straightforwards. However due to a combination of factors, this trip in late 2023 had more issues than that much longer journey of 2016. Here’s how it went.
Day 1
The 28th and 29th December are some of the worst days of the year to travel, as half the staff are on holiday, almost everyone in the world is travelling for holidays or family visits, and the weather is terrible.
Storm Gerrit (yes, really) blew a tree onto the line to London the night before I left. Impressively it was clear by 8AM. However, 2 previous trains to London were cancelled so three train loads of people crammed into one, barely fitting. A common experience in the UK in 2023. The staff created some order from the chaos and I guess everyone was just happy to make it to London only 30 minutes late.
I got to the Eurostar terminus with about 60 minutes to go through the border checks and no time to grab any food. This was only just enough time. There seemed to be only 1 guard checking every single UK passport and he wasn’t in a rush. I made it to the train, but I would be surprised if everyone who was further back in the queue managed to make it through.
The journey to Paris was pleasantly uneventful. In fact, nothing more went wrong until I was across the border into Spain.
The last time I did this overland trip, I went via Paris and Barcelona. The weakest point of that trip in terms of infrastructure is going between Barcelona and France border: there are 2 very expensive fast trains; or you can a take a 3 hour metro train to Latour de Carol and a night train. This route is vulnerable to delays - if you miss a connection you may need a last-minute hotel in Paris or Barcelona, which is an expensive problem.
So I took the route recommended by the Interrail app and by the Man in Seat 61, via Hendaye and Irún. Having left at 07.45 UK time, I got to Hendaye 22:45 French time and walked 20 minutes to a nice hotel in Irún. 50€ for a single room. Much cheaper than Paris!
Day 2
There’s one train a day direct from Irún to Madrid, leaving at 08.45. I was going to catch it to Segovia and then head to Santiago arriving around 17.00. Pretty good for a 1000km+ journey across the entire width of Spain.
At 08.47 I watched that train leaving Irún on time and with an empty seat where I should have been.
My mind doesn’t work right at 08:00. I left the hotel and walked away from the station, without checking – I got right back to the French border before realizing my mistake. Running, I got back to the station area and then got lost again trying to find the way in. The regular entrance is closed. The temporary entrance is pictured below… can you see it?
Yes… that tiny staircase at the end of the plaza. Perhaps a sign or two would help dumb travellers like me from getting lost and day 2 might have had a happier start.
Missing a high speed train can be an expensive mistake. Booking new tickets on the day can cost 200€ or more. If there are tickets available at all. Spanish trains require everyone to have a seat reservation, and if there are no more seats then the train is marked as “Full” and you can’t travel. There’s no possibility of standing room here.
I asked for help in the Irún ticket office and the lady was not optimistic about my chances. I had two things on my side though. The Interrail pass meant I didn’t need full tickets, I only paid around 15€ for new seat reservations. And as luck would have it, 1 place remained on the slow train to Galicia that day, which became mine.
So thanks to my early morning cockup I got home for 23:30. A long day – I expected to arrive at 17:00 – but a decent option. My other options would have been an 18 hour bus along the coast, or an expensive domestic flight.
The good and the bad
Why does the train journey get a 1500 word blog post, while the equivalent journey by plane does not?
Air travel can also be complicated – once, Vueling simply cancelled my flight on the day of travel, without notification and no viable alternative route, requiring an expensive new ticket to Porto and an overnight bus. It didn’t make an interesting blog post though. Events like this are covered in the mainstream press all the time, while cross-border train travel is still considered a minority pursuit.
I hope we get to a point where cross-border rail travel becomes mainstream and boring. We need alternatives to air travel. Every overland trip you do is worthwhile to show interest in these alternative routes. To look at it another way, you can’t complain about the trains being shit if you never try to use them. In a year where despots and colonizers are sending fighter jets and bombers to destroy the homes and the lives of innocent people in Ukraine and Palestine, by comparison the commercial aviation industry looks pretty innocent. But it causes somewhere between 4% and 10% of all greenhouse gas emissions and the figure is rising.
Besides funding less CO² emissions the train route has advantages: comfortable seats, better scenery, better baggage allowance with no worries about what might be classified as a liquid, and friendly staff along the way. I got some work done — almost all the trains had power sockets, and in France there’s even on-board wifi that works.
Organising a trip like this requires expertise. The Interrail app requires some practice. The Hendaye / Irún border doesn’t appear in most booking websites. The Seat 61 website is an invaluable resource when organising overland trips. There are also travel agents who do this if you have extra money to burn.
Cost
Talking of money, how much did it cost?
The Interrail pass was 258€. I used it to travel in the UK so it covered at least €125 of train fares there, let’s say 125€ went towards the trip home. The big problem is the Eurostar ticket – nearly 200€! Seat reservations were another 40€, and I paid 50€ for a hotel in Irún, so let’s say the total trip cost was 415€.
Compared to a flight – my family don’t live near any airport, so cheap early-morning flights aren’t an option. In this December period I expect to pay 200€ for a London-Santiago flight including baggage, plus 100€ to get to Gatwick by train, so around 300€ in total. Cheaper but comparable.
How do we make the train route practical?
The biggest blocker is time, of course – 30 to 40 hours is a whole weekend. I don’t get enough time off work to spend 4 days of each trip on travel. Working on the train isn’t realistic either; some of my work is commercially sensitive, and I can’t reasonably ask the person next to me to sign an NDA. Also, Spain there is no internet on the train, and in the UK there are no seats.
The Eurostar is in crisis, it is significantly worse since Brexit, and that one dude slowly stamping every passport is certainly not able to handle any more passengers per hour. Since capacity is limited through the station, prices for the Eurostar are prohibitively expensive. Airports have more than one passport gate – why not St. Pancras Station? This is a political issue which requires political will to solve.
France and Spain need to cooperate more on rail travel. Things have actually got worse in this regard. Imagine if SCNF ran a train to Irún, or Renfe had a train starting in Hendaye – the line is there, just – again – the political will is not.
Beyond that, making the city connections join up nicely would help hugely. The railways in Paris follow the famous “Legrand Star” design, which means you probably have to travel 30 minutes by metro to make any long distance train connection. This just isn’t practical if you have reduced mobility or small children in your party.
If you’re interested in this stuff – which you must be if you read down to here – I highly recommend following Jon Worth who seems to be the most rational and realistic voice in this area at the moment, and the #CrossBorderRail hashtag on the Fediverse.
Anyway, here’s to a 2024 filled with fun travel plans!
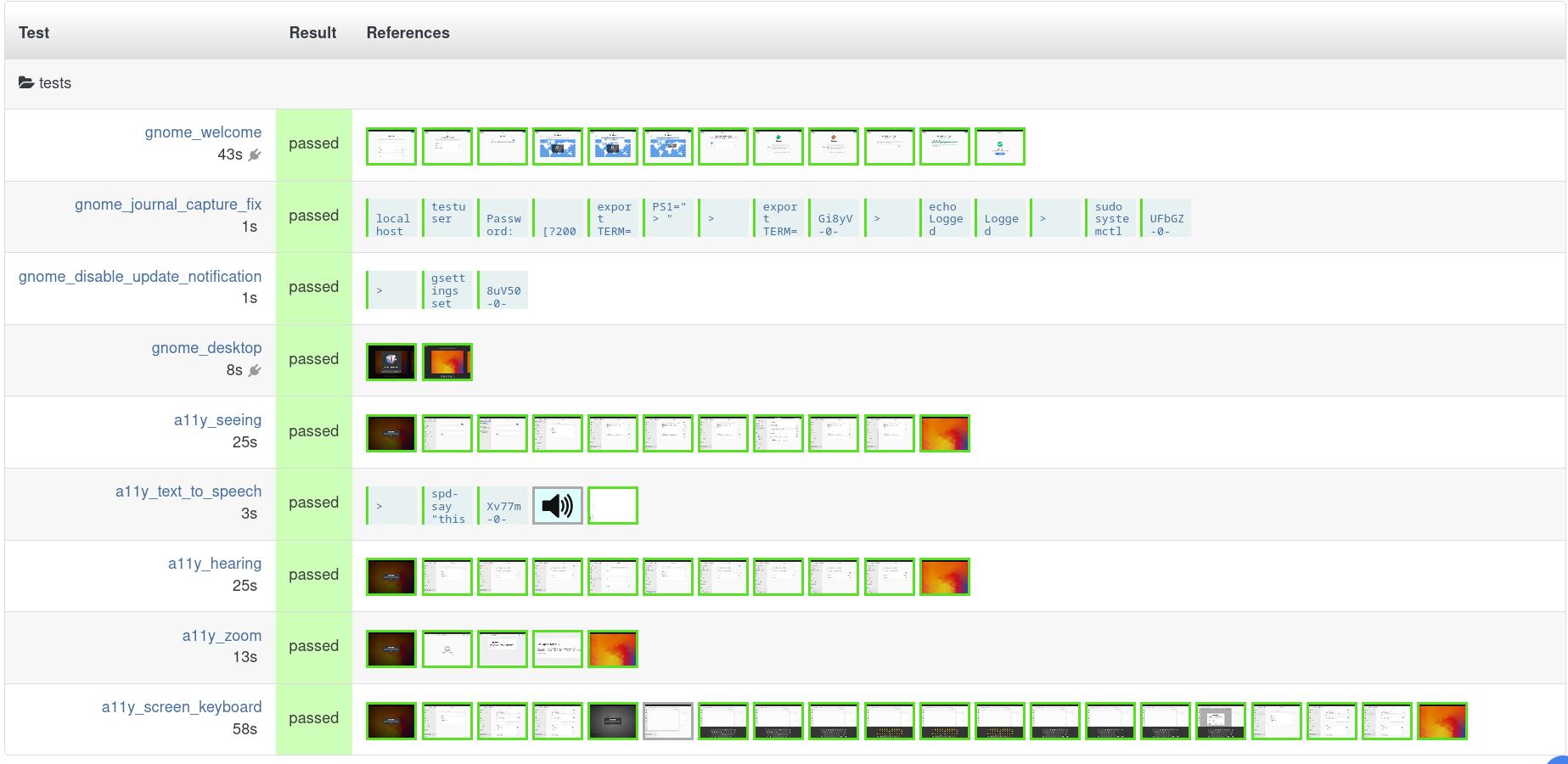
The Outreachy intership for end-to-end testing of GNOME OS started this month, and we are already in week 3 of the internship. Our two interns Dorothy and Tanjuate are working hard on the first phase which is testing accessibility-related features. Here’s what we’ve achieved so far:
Add a gnome_accessibility testsuite so all a11y related tests appear in one place
Extend the app_settings test in gnome_apps testsuite so it switches on dark mode
This caught a crash in libjxl via GNOME Settings
Create tests for all “Seeing” a11y features in GNOME Settings
These enable the settings one by one and test the Settings app looks as expected with the new settings
Create test for screen reader
The test works but the speech output is garbled
We are adding some finer grained tests to ensure audio and Speech Dispatcher work separately to Orca
Create test for “Overamplification” option in “Hearing” settings
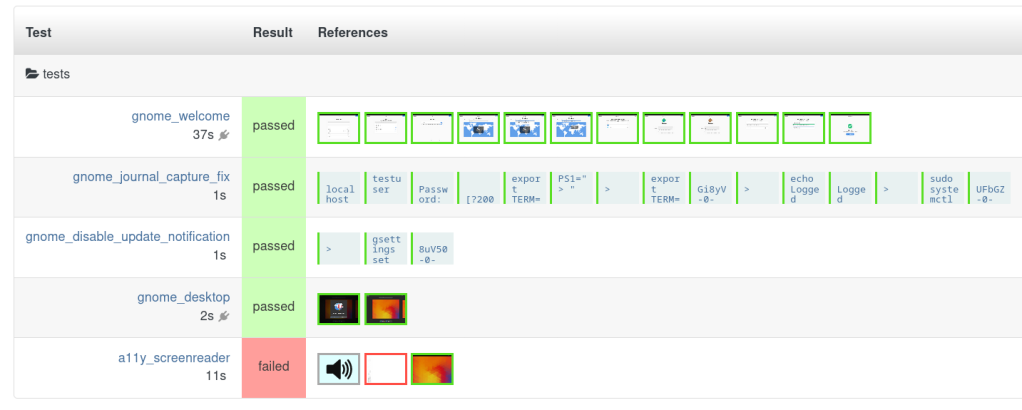
The work-in-progress gnome_accessibility testsuite
Outreachy recommend blog post topics for the interns. and this week’s is “Everyone Struggles.” There are still a whole load of technical struggles when I work with the openQA tests which test my own patience. Here are some of them:
On some CI runners, tests never start. It seems to be network related – the openQA worker log says something about missing WORKER_HOSTNAME. The next step will be to add some debugging to .gitlab-ci.yml to try and diagnose what’s different on the two workers that don’t work.
GNOME Shell doesn’t always start when gnome-initial-setup should run. There’s an error about read-only GVFS metadata. This doesn’t reproduce very often, so I can’t easily investigate. Valentin came up with a possible solution, but it seems it didn’t solve the issue and we need to keep trying.
The CI pipeline that runs the tests takes about 15 minutes, and almost 5 minutes are just downloading large OS artifacts from S3. The artifacts are already compressed (in fact another minute is spent running unxz). I don’t know how we can improve this,
The end-to-end tests can’t run on gnome-build-meta merge requests, only on the master branch, due to an infrastructure issue that is stuck.
Creating needles is too difficult. I documented a manual approach, which is useful for learning but too fiddly for ongoing use. The openQA web UI has a reasonable editor, but the interns don’t have GNOME LDAP accounts so they can’t access it, and the “developer mode” can’t be used anyway. We’re currently trying running a demo instance of the webUI locally using Podman, there’s more work to do before this is a fully usable workflow for test development though.
GNOME OS is migrating from OSTree to systemd-sysupdate, we need to switch to using the new images in the tests, but we need to update os.gnome.org to make the new images downloadable first.
I am happy that we’re working through these issues, that was partly why I was excited to run an internship around the end-to-end tests. Hopefully this gives you some idea on how hard we are working on QA for GNOME !
In Santiago we are just coming out of 33 consecutive days of rain. The all-time record here is 41 consecutive days, but in some less rainy parts of Galicia there have been actual records broken this autumn. It feels like I have been unnaturally busy but at least with some interesting outcomes.
I spent a lot of time helping Outreachy applicants get started with openQA testing for GNOME. I have been very impressed with the effort some candidates have put in. We have come a long way since October when some participants had yet to even install Linux. We already have a couple of contributions merged in openqa-tests (well done to Reece and Riya), and some more which will hopefully land soon. The final participants are announced next Monday 20th November.
Helping newcomers took up most of my free time but I did also make some progress on openQA testing for apps, in that, it’s now actually possible 🙂 Let me know if you maintain an app and are interested in becoming an early adopter of openQA!
This month I had the pleasure to visit Manchester and Wales for a couple of weeks. I caught the last of the summer before the crazy climate-crisis storms of October began and everywhere started flooding.
I also just came back from A Coruña where I attended the excellently organised X.org Developers Conference. Thankfully there were no talks about X.Org, but we did talk a lot about managing hardware test rigs. This is a problem that Mesa 3D developers are particularly interested in, given the nature of that project, and it’s increasingly relevant for GNOME as well. It was also great to catch up with some folk I hadn’t seen since before the Great Plague or who I’d never even met in real life before.
Outreachy
I decided that the GNOME openQA tests were a good candidate for running an Outreachy internship. Initially I thought I would run a project to test GNOME with mobile form factor. After chatting to Sonny we came up with a much more interesting plan which helped me to re-evaluate my whole approach to these kinds of internships.
I have been involved in Google Summer of Code in the past, once as an intern and once or twice as a mentor. I think in all cases it’s been useful for the intern, and we have had some great interns, but it’s not always super useful for the project.
The difficulty is: allocating a task that is exactly 3 months long is quite difficult, and the task ends up being something that an experienced developer might do in a week, which you arbitrarily draw out to 3 months and turn into a teaching opportunity. I am yet to mentor someone who has later become a long-term contributor to the same project. Parcelling out appropriate tasks in active project is a headache – for example, once an applicant submitted a merge requst during the application period that already implemented a big part of one project.
Sonny ran an internship for Workbench this year where the goal was to add as many platform demos as possible. So instead of one big task, it involves many smaller tasks. This avoids all of the issues I mentioned above. Each contribution during the application period can be actually useful, and you can have multiple interns collaborating, or just one.
This is especially nice for this year since GNOME has funding for 3 interns, and the openQA tests project is our only proposal.
So I have spent a lot of time in the #GNOME OS room on Matrix the last few weeks helping applicants to run the openQA tests and contribute small modifications. We have a bunch of ideas for tests to add – please add more here if you have them. Some may become essential and others perhaps won’t work at all – trying different ideas in parallel we’ll definitely have some useful outcomes for GNOME.
Github Security Lab
Carlos already posted about the exploit in Tracker Extract found by Github Security Lab. I don’t have much to add, except to echo that the reporter, Kevin Backhouse, dealt with this report in a really helpful way, and Carlos himself did some heroic work to rework the entire main loop of tracker-extract works in the space of a weekend. You can take a look at the branch here.
That’s not the whole story, SECCOMP sandboxing is an ongoing pain in the butt to maintain; it’s one of those things that has to be funded in order to happen, as very few people will do this kind of work voluntarily – the main issue, I think, is that success here is invisible. It’s an absense of security holes. An absence of test failures. And it’s hard to celebrate and take credit for doing stuff that nobody will notice until it goes wrong.
So while its great to see Microsoft (and Google) funding research into potential vulnerabilities in GNOME, let’s remain realistic that the best way to ensure high quality GNOME releases is to commit funding for the maintainers who deal with these issue reports.
Musically this has been a fun month. One of my favourite things about living in Galicia is that ska-punk never went out of fashion here and you can legitimately go to a festival by the sea and watch Ska-P. Unexpectedly brilliant and chaotic live show. I saw an interview recently where Angelo Moore of Fishbone was asked by a puppet what his favourite music is, and he answered: “I like … I like the Looney Tunes music”. Same energy.
I wrote already this month about my DIY media server and the openQA CLI tool. This post contains some brief thoughts about Nushell and then some lengthy thoughts about the future of the Web. Enjoy!
Nushell everywhere
I read a blog by serial shell innovator JT entited “The case for Nushell”. I’ve been using Nushell for data-focused work for a while and the post inspired me to make it my default shell in a few places.
Nushell is really comfortable to use these days, it’s very addictive the first time you construct a one-liner to pretty-print some JSON or XML, select the fields you want and output a table as Markdown that you can paste straight into a Gitlab issue. My only complaint is the autocomplete isn’t quite as good as the Fish shell yet. (And that you can’t type rm -R… like chown and chmod only accept -R, and now rm only accepts a lower case -r, how am I supposed to remember that guys???)
I have a load of arcane Bash knowledge that I guess I’ll have to hang onto for a while yet, particularly as my job mostly involves SSH’ing into strange old machines from the 1990s. Perhaps I can try and contribute Nushell binaries that run on HP-UX and Solaris. (For the avoidance of doubt, that previous sentence is a joke).
Kagi Small Web
There’s a new search engine on the block called Kagi which is marketed as “premium search engine”, you pay $0.05 per search, and in return the results are ad-free.
I like this idea. I signed up for the free trial 100 searches, and I haven’t got far with them.
It turns out most of the web searches I do, are things I could search on a specific site if I wasn’t so lazy. For example I search “rust stdio” when I could go to the Rust documentation on my local machine and search there. Or I search for a programming problem when I could clearly just search StackOverflow itself. DuckDuckGo has made me lazy; adding a potential $0.05 cost to searches firstly makes you realize how few you actually need to do. Maybe this is a good thing.
Anyway, Kagi. They just launched something named Kagi Small Web, which is announced here:
Kagi Small Web offers a fresh approach by promoting recently published content from the “small web.” We gather new content, published within the last week, from a handpicked list of blogs and surface it in multiple ways:
Directly within Kagi search results for applicable queries (existing Kagi members do not need to do anything, this will be automatic)
Via the new Kagi Small Web website
Through the Kagi Small Web RSS feed
Via our Search API, where results are now part of the news enrichment API
Initially inspired by a vibrant discussion on Hacker News, we began our experiment in late July, highlighting blog posts from HN users within our search results. The positive feedback propelled the initiative forward. Today, our evolving concept boasts a curated list of nearly 6,000 genuine websites featuring people with a wide variety of interests.
When I first saw this my mind initially jumped to the problematic parts. Who are these guys to suddenly define what the Small Web is, and define it as a a club of some 6,000 websites chosen by Hackers News? All sites must be in English, so is the Web only for English speakers now?? More importantly, why is my site not on the list? Why wasn’t I consulted??
There’s also something very inspiring about the project. I try to follow the rule “something is better than nothing”, and this project is a pretty bold step forwards, which inspired a bunch of thoughts about the future of The Web.
Google Search is Dying
Since about 2000, when you think of the Web, you think of Google.
Google Search has been dying a slow, public death for about the last ten years. Google has been too big to innovate since the early 2010s (with one important exception, the Emoji Kitchen).
Google Search remained king until now for two reasons: one, their tech for turning hopelessly vague search queries into useful results was better than anyone’s in the industry, and two, as of 2023, almost nobody else can operate at the scale needed to index all of the text on the Web.
I guess there’s a third reason too, which is spending billions of $$$ to be the default search provider nearly everywhere, to the point that the USA is running an antitrust hearing against them, but let’s focus on the technical aspects.
The current fad for large language models is going to bring big changes to the Web, for better or worse. One of those is that “intent analysis” is suddenly much easier than it was. Note, I’m not talking about prompting an LLM with a question and presenting the randomly generated output as an answer. I’m talking about taking unstructured text, such as “trains to London” and turning it into an actionable query. A 1990’s era search engine would throw away the “to” return any website that contained “trains” and “London”. Google Search shows a table of live departure times for trains heading to London. (With some less useful things above and below, since this is the Google Search of 2023).
A small LLM such as Vicuna can kinda just DO this stuff, not perfectly of course, but its an order of magnitude easier than a decade ago. Perhaps Google kept their own LLM research internal for so long for fear of losing exactly this edge? The “We have no moat” memo suggests fear.
Onto the second thing, indexing all the content on the Web. LLMs don’t make this easier. They make it impossible.
Its now so easy to generate human-like text on the Web using machines, that it doesn’t make sense to index all the text on the Web any more. Much of it is already human-generated generated garbage aiming to game search ranking algorithms (see “A storefront for robots” for fun examples).
Very soon 99% of text on the web will be machine generated garbage. Welcome to the dark forest.
For a short time I was worried about this, but I think it’s a natural evolution of the Web. This is the end of the Olde World Wide Web. What comes next?
There is more than one Small Web
If you’ve read this far, firstly, thanks and well done, in 2023 its hard to read so many paragraphs in one go! I didn’t even put in single video.
Let me share the insight I had on thinking over Kagi Small Web. Maybe it’s obvious and maybe it isn’t.
A search engine of 6,000 websites is small-scale enough that one person could conceivably run it.
Let’s go back a step. How do you deal with a Web that’s 99% machine-generated noise? I imagine Google will try to solve this by using language models to detect if the page was generated by a language model, triggering another fairly pointless technological arms race against the spammers who will be generating this stuff. This won’t work very well.
The only way for humans to make sense of the new Dark Forest Web is to have lists of websites, curated by humans, and to search through those when we want to find information.
If you’re old you know that this isn’t a new idea. In fact, we kinda had all of this stuff in the form of web rings, link pages on other people’s websites, bookmarking services, link sites like Digg, Fark and Reddit, RSS feeds and feed readers. If you look at Kagi Small Web reader site it’s literally a web ring. It’s StumbleUpon. It’s Planet GNOME. But through the lens of 2023, it’s also something new.
So I’m not going to start reading Kagi’s small web, though it may be great. And I’m going stop capitalising “small web”, because I think we’re going to curate millions of these collectively, in thousands of languages, in infinite online communities. We’re going to have open source tools for searching and archiving high quality online content. Who knows? Perhaps in 10 years we’ll have small web search tools integrated into GNOME.
As a Linux hacker-type I am often searching for some way to apply my rather specialized skillset to a real world problem. And I am always after some sovereignty over my music collection. So I came up with the idea to make some kind of music player using a Raspberry Pi in an old radio case.
What I wanted
What I got
In 2020 I got as far as setting up the Pi, in a cardboard box rather than the imagined retro radio case. It’s worked mostly ok since then, I always had some friction with the Raspbian Linux distribution though; I mean Debian is not the most up-to-date distro, and Raspbian is not even up to date with the latest Debian release. But Raspbian was the only OS with sufficient driver support to be useful for workloads involving graphics, audio, or Bluetooth.
Until now, it seems! After lots of great work from various folk, Fedora now has full Pi support, using a UEFI bootloader, with graphics acceleration, etc.
Recently I did that thing where you try to mix packages from Debian repos, thinking you might be able to do it safely this time, and the system winds up broken beyond repair, as usual. So I decided to throw it away and start again on top of the rpm-ostree based Fedora IoT distro.
The Pi is now back in action and mostly working, and the setup experience was tolerable. Here’s a summary of what I did.
The Base
It’s a Pi 4 connected to:
a TV via HDMI
an external HD via USB
ethernet via a cable
The Fedora IoT install instructions are good, although somehow I didn’t get the right SSH key installed and instead had to set init=/bin/sh on first boot to gain access.
I created a regular user named “pi” and did the usual prep for a toy system: disable SELinux and disable firewalld, to avoid losing precious motivation on those.
I want to access the Pi by name; so I enabled Multicast DNS in the systemd-resolved config, and now I can refer to it with a name like pi.local on my home network.
All of the setup is automated in Ansible playbooks, when I break the machine I can rebuild it without having to go back to this blog post.
Audio
The Pi’s analogue audio output isn’t supported in Fedora IoT 38, but HDMI audio is. HDMI audio is handled by Broadcom VideoCore 4 hardware, driven by the vc4 driver.
As of Fedora IoT 38 this driver is blocklisted on the kernel commandline, and HDMI audio devices only appear after running modprobe vc4. Removing the block caused Bluetooth to stop working; I don’t really want to know what’s going on here, so instead I added a systemd unit to run modprobe vc4 after basic.target, and moved on.
I also had to add my pi user to the audio system group, done using systemd-sysusers in `/etc/sysusers.d`. Now I can see the audio devices, and (once installed) so can Pipewire and Wireplumber:
Amazingly, using aplay I can now play audio from my TV.
Bluetooth
The Pi has a combined Bluetooth+Wifi adapter, the BCM4345C0. By default this needs manual probing with bcattach to make it appear. Following the overlays README, we can add this line to cat /boot/efi/config.txt for it to appear automatically on boot:
dtparam=krnbt=on
You can confirm it’s working by checking if /sys/class/bluetooth/ is populated with the hc0 controller.
From there I followed this guide from our friends at Collabora, “Using a Raspberry Pi as a Bluetooth speaker with PipeWire” and, rather amazingly, I managed to cast from my phone to the television a couple of times, after manually trusting and connecting the device from bluetoothctl on the commandline.
Ideally I want to be able to stream audio without having to get out my laptop and log in to the speaker via SSH each time I arrive home so that it connects to my phone. Another short Python script named bluetooth-autoconnect solves that by watching for trusted devices to appear and connecting with them automatically. So I only have to SSH into the machine once per device to set it as trusted.
I still get connection failures sometimes, restarting Wireplumber usually works around those.
External hard disk
The external HD full of music and media doesn’t get automatically mounted, so I installed UDisks2 and udiskie to automatically mount it. I added a storage group containing my ‘pi’ user, and a service running udiskie as ‘pi’ so that the external disk is mounted by this user.
The external disk I used was NTFS-formatted, which was a terrible idea. Every time the machine booted the filesystem would be marked dirty, no matter how cleanly I unmounted it before shutdown. I gave up on NTFS and copied the data to a second disk which is ext4-formatted.
NTFS: just say no.
Kodi
I figured getting the Kodi media server to work would be the biggest challenge. On Raspbian it’s as simple as apt install kodi and everything just works, but Fedora don’t even package Kodi (presumably due to patent issues?).
The right way to do this is to use Flatpak. The ARM64 build of Kodi is now ready. (Pro tip, you can push a draft PR to test your changes on the Flathub ARM builder rather than spending a week building it on an emulated ARM device on a small laptop.)
Flatpak needs a display server to work with, and my plan is to run a minimal Weston compositor following these instructions.
Other services
For completeness, here are the other services I’m running. These are all containers, in keeping with the design of Fedora IoT.
One very nice thing of switching from Docker to Podman is the improved systemd integration. If you just deploy a container then it doesn’t persist across reboots, so you need a systemd service as well. Podman can generate these, and Ansible’s containers.podman.podman_container module makes it easy. The Ansible playbook to deploy Samba looks like this:
- name: Samba container
containers.podman.podman_container:
name: samba
...
# Let systemd manage service
restart_policy: "no"
generate_systemd:
path: ~/.config/systemd/user
restart_policy: on-failure
- name: Start systemd unit
systemd_service: daemon_reload=true name=container-samba state=restarted scope=user
No need to manually create a systemd unit for each container any more \o/
Calliope + Beets + Tracker Miner FS will be the next step, but first I need to bulid an ARM64 compatible container containing all the necessary pieces.
And perhaps that retro radio case – I do have some old cassette walkmans that might do the job.
Have you got any small home servers running? Show me!
Hello! As often, these are some thoughts without any grand announcements to accompany them.
It’s just passed 5 years since I arrived in Santiago de Compostela, without much of a plan, and here I am. Summer a bit milder than last year which is great as I have got really back into cycling again. Compostela apparently has the highest ratio of tourists to locals at the moment in all Spain – 1.3 visitors for every resident, its very noticeable if you go to the old town. Meanwhile in the UK even Conservative news outlets now recommend leaving. I personally miss UK life but what I really miss is the UK of 2013, before the last decade of Conservative-led self destruction.
I already posted about GUADEC and not much has happened since. I have done some development on a Raspberry Pi-based home media server that, until recently, ran Raspbian and now runs Fedora IoT. I wanted to test an OSTree-based OS for a while and this seemed like a good opportunity as Fedora recently gained support for the Pi’s GPU.
The atomic updates with rpm-ostree work really nicely, it can be slow on ARM + SDcard, but that’s a good incentive to keep the base OS small and use containers for hosted services. This change in approach from “distro packages are the best option” to “containers are the best option” is what makes this migration non trivial.
Raspbian and Debian very much encompass the “traditional distro” model where all usecases should be satisfied with packages. Some folk still claim this to be the One True Way. In an ideal world I would agree. When it works well the results are great, the Kodi package on Raspbian is a great example which *just works*, thanks to hard work by many people. That said, Debian isn’t the newest collection of packages and Raspbian is not even based on the newest Debian release. It’s not even 64-bit by default. If I did have time to try and push these efforts forwards, where would I start?
Containers are not a panacea. Configuring services by adding snippets of config file into different environment variables can be maddening. But I am enjoying the “small distro” concept overall and finding suitable containers for different services hasn’t been difficult. So what about Kodi?
There is a Flatpak for Kodi and installing Flatpak on the Pi was not difficult. The Kodi Flatpak is only available for x86_64, though. How hard can it be to build for arm64?
Well, as always Hubert Figuiere already made a start. I updated his PR here. Building it locally on my laptop using flatpak-builder and qemu-system-arm took most of this week, and the resulting binary manages to load and display its UI, which is surprisingly good progress. The process doesn’t respond to keyboard input, so when I have a free minute I get to do some more debugging. Let’s see how it goes before I get bored.
This blog is about what’s on my mind, and recently I’ve been thinking about aeroplane flights, and limiting how many I take every year.
I’m not trying to make anyone feel impressed or ashamed here, or create rules that I insist everyone needs to live by. And I am no expert in climate science, but we need to start talking about this stuff more – as you probably spotted, the climate is uncomfortably hot now, caused mainly by all the “greenhouse gases” that we keep producing in our industrious human civilization.
Commercial aviation accounts for 3.5% of global warming today, according to the 3rd result in a web search I just did. So planes aren’t the biggest issue – the biggest issue is a massive methane leak from an oil well in Turkmenistan, and I guess the best contribution I could make to avoid further heating would be to plug up that hole somehow. From here though, it seems more realistic for me to look at reducing how much money I give to airlines and oil companies.
Plane spotting
In 2020 I didn’t go anywhere due to the COVID pandemic. so lets start with 2021.
2021: 3 flights, 6 hours total. (Including work stuff, family visits for Christmas).
2023: So far, 6 flights, 6 hours total (the usual, plus FOSDEM and an incredible bike holiday in Wales)
My current goal is that 2023 will have no more flights than 2022. I’ve started tracking them in a spreadsheet to make me think harder about avoiding them. It’s easy to get excited about a holiday, conference, concert etc. and forget about the broader goal of not taking flights all the time. It’s also very hard to avoid them all – I’m sure I will take a flight to GUADEC in Latvia next month, which is basically as far away from me as you can get without leaving Europe. (I am hoping I can take a boat to the UK afterwards though, let’s see).
Everybody’s circumstances are different of course. I chose to live 2000km from my family, which implies extra travel. Some folk live 20,000km from their family, which implies even more. There’s no point judging people for how their life turned out. (Although it is good to judge billionaires and politicians flying everywhere in private planes – fuck those guys!!!).
My last trip from the UK supposedly avoided 4% of emissions of one passenger by using “sustainable fuel”, so that’s about 0.03% of the total emissions, and they emailed me this nice certificate.
The aviation industry claim that flying is actually great anyway, soon aeroplanes will be powered solely by wildflowers and insect wings, etc. etc. This is exactly what a business that sells plane tickets would say, so I am skeptical, and there is plenty of evidence of “greenwashing” such as this recent “Science Based Target Initiative“. Ultimately its hard for airline managers to turn down a fat targets-related bonus just to try and help the future of civilization … a sort of “prisoners dilemma”.
Rambling about trains
Many people assume you can take a boat between the UK and Spain, and you can do but the boat takes over 25 hours and leaves you in either Santander or Portsmouth, neither of which are very well-connected.
High speed trains are a better option, and they already exist for most of the trip: Santiago – Barcelona is less than 8 hours (not bad to travel 1000km); and Paris -> Manchester is also only 6 hrs door to door (to go 800km). The missing piece for me is Barcelona to Paris.
There’s no sleeper train option between Spain to France, since the Spanish government decided to remove it in 2012. During the day there about 2 trains, which take 6 hours each, unfortunately 8 hrs + 6 hrs + 6 hrs makes 20 hrs means you can’t do this trip in a single day. You need an expensive hotel either in Barcelona or Paris to make the trip in addition to that expensive express train to Paris. So I’ve only taken this route once so far, and it involved a few days in the French Pyrenees. (As an aside, that would be an option for every trip if it wasn’t for the restrictions of my job! In fact most of these issues would be more tractable if I could work less days a week or just take days offline sometimes.)
The French government have seen sense already and run excellent night trains from the border up to Paris, but the Spanish government have not seen any sense at all, and the connections from Barcelona are hopeless. There is some hope though, from the European Sleeper cooperative who are working on a Barcelona -> Brussels night train, due some time in 2024/2025. That could make the Santiago -> Manchester trip feasible overland in around 24 hours – which would be incredible!! They are running a share offer at the moment, if you find that sort of thing interesting.
So that’s what’s on my mind as the hot summer weather picks up across Europe.
As I said above – I’m not posting this in order to feel superior to folk who travel more by aeroplane, nor to show off about being part of the lucky 20% of people who are able to travel by aeroplane at all.
But I would like to see more people talking openly about the future and the climate crisis. When you have a problem, usually the hardest thing is to talk about it. It requires you to admit that there is a real problem which is not much fun. A lot of oil companies would prefer that we stay in denial. (They are happy making record profits!). Stay safe out in the heat.
I did some research into open source text to speech solutions recently. As part of that I spent a while trying out Coqui TTS and, while I was trying to get it to sound nice, I learned a few things about voice synthesis.
Coqui TTS provides some speech models which are pre-trained on specific datasets. For text-to-speech, each dataset contains text snippets paired with audio recordings of humans reading the text.
Here is a summary of some of the available open datasets for English:
ljspeech: audio recordings taken from LibriVox audio books. One (female) speaker, reading text from 19th and 20th century non-fiction books, with 13K audio clips.
VCTK: 110 different speakers, ~400 sentences per speaker
Sam: a female voice actor (Mel Murphy) reading a script which was then post-processed to sound non-binary. There’s an interesting presentation about gender of voice assistants accompanying this dataset. ~8 hrs of audio.
Blizzard2013: A voice actor (Catherine Byers) reading 19th & 20th century audio books, focusing on emotion. Released as part of Blizzard 2013 challenge. ~200 hrs of audio.
Jenny: a single voice actor (again, female) reading various 21st century texts. ~30 hrs of audio.
There’s a clear bias towards female voices here, and a quick search for “gender of voice assistant” will turn up some interesting writing on the topc.
There are then different models that can be trained on a dataset. Most models have two stages, an encoder and a vocoder. The encoder generates a mel spectogram which the vocoder then uses to generate audio samples. Common models available in Coqui TTS are:
Reading a computer screen wears out your delicate eye-balls. I would like the computer to read some web-pages aloud for me so I can use my ears instead.
Here’s what I found out recently about the available text-to-speech technology we have on desktop Linux today. (This is not a comprehensive survey, just the result of some basic web searches on the topic).
The Read Aloud browser extension
Read Aloud is a browser extension that can read web pages out for you. That seems a nice way to take a break from screen-staring.
I tried this in Firefox and, it worked, but sounded like a robot made from garbage. It wasn’t pleasant to listen to articles like that.
Read Aloud supports some for-pay cloud services that probably sound better, but I want TTS running on my laptop, not on Amazon or Google’s servers.
Speech Dispatcher
The central component for text-to-speech on Linux is Speech Dispatcher. Firefox uses Speech Dispatcher to implement the TTS part of the Web Speech API. This is what the Read Aloud extension is then using to read webpages.
You can test Speech Dispatcher on your system using the spd-say tool, e.g.
spd-say "Let's see how speech-to-text works"
You might hear the old-skool espeak-ng voice robotically reading out the text. espeak was incredible technology when it was released in 1995 on RISC OS as a 7KB text-to-speech engine. It sounds a little outdated in 2023.
Coqui TTS
Mozilla did some significant open research into text-to-speech as part of the “Mozilla TTS” project. After making great progress they stopped development (you may have heard this story before), and the main developers set up Coqui AI to continue working on the project. Today this is available for you as Coqui TTS.
You can try it out fairly easily via a Docker image, the instructions are in the README file. I spent some time playing with Coqui TTS and learned a lot about modern speech synthesis, which I will write up separately.
The resource consumption of Coqui TTS is fairly high, at least for the higher quality models. We’re talking GBs of disk space, and minutes to generate audio.
It’s possible that GPU acceleration would help, but I can’t use that on my laptop as it requires a proprietary API that only works on a certain brand of GPU. It’s also likely that exporting the models from PyTorch, using TorchScript or ONNX, would make them a lot more lightweight. This is on the roadmap.
Piper
Thanks to an issue comment I then discovered Piper. This rather amazing project does TTS at a similar quality to Coqui TTS, but additionally can export the models in ONNX format and then use onnxruntime to execute them, which makes them lightweight enough to run on single-board computers like the Raspberry Pi (remember those ?).
It’s part of a project I wasn’t aware of called Home Assistant, which aims to develop an open-source home assistant, and is being driven by a company called Nabu Casa. Something to keep an eye on.
Thanks to Piper I can declare success on this mini-project to get some basic screen reading functionality on my desktop. When I get time I will write up how I’ve integrated Piper with Speech Dispatcher – it was a little tricky. And I will write up the short research I did into the different Coqui TTS models that are available. Speak soon!
I am volunteering a lot of time to work on testing at the moment. When you start out as a developer this seems like the most boring kind of open source contribution that you can do. Once you become responsible for maintaining existing codebases though it becomes very interesting as a way to automate some of the work involved in reviewing merge requests and responding to issue reports.
Most of the effort has been on the GNOME OpenQA tests. We started with a single gnomeos test suite, which started from the installer ISO and ran every test available, taking around 8 minutes to complete. We now have two test suites: gnome_install and gnome_apps.
The gnome_install testsuite now only runs the install process, and takes about 3 minutes. The gnome_apps testsuite starts from a disk image, so while it still needs to run through gnome-initial-setup before starting any apps, we save a couple of minutes of execution. And now the door is open to expand the set of OpenQA tests much more, because during development we can choose to run only one of the testsuites and keep the developer cycle time to a minimum.
Big thanks to Jordan Petridis for helping me to land this change (I didn’t exactly get it right the first time), and to the rest of the crew in the #gnome-os chat.
I don’t plan on adding many more testsuites myself. The next step is to teach the hardworking team of GNOME module maintainers how to extend the openQA test suites with tests that are useful to them, without — and this is very important — without just causing frustration when we make big theming or design changes. (See a report from last month when Adwaita header bars changed colour).
Hopefully I can spread the word effectively at this year’s GUADEC in Riga, Lativia. I will be speaking there on Thursday 27th July. The talk is scheduled at the same time as a very interesting GTK status update so I suppose the talk itself will be for a few dedicated cats. But there should be plenty of time to repeat the material in the bar afterwards to anyone who will listen.
My next steps will be around adding an OpenQA test suite for desktop search – something we’ve never properly integration tested, which works as well as it does only because of hard working maintainers and helpful downstream bug reports. I have started collecting some example desktop content which we can load and index during the search tests. I’m on the lookout for more, in fact I recently read about the LibreOffice “bug documents” collection and am currently fetching that to see if we can reuse some of it.
The format can be improved here, but it already makes it quicker for me to turn a test failure into a bug report against whatever component probably caused the failure. If you introduce a critical bug in your module maybe you’ll get to see one soon 😉
It’s been a long month, thankfully with a nice holiday in the middle. I am divided between lots of things at work which is not helpful for being able to focus on any interesting thing.
The development of large language models is everywhere at the moment, I shared some thoughts on those on the Lines forum. I won’t go in depth here as we’re going to be discussing these things for the next 15 years anyway. Stay safe out there in the dark forest.
I’ve had a little time to poke at GNOME’s OpenQA tests. I made a simple helper tool named ssam_openqa which simplifies the task of running the OpenQA tests locally on your laptop. My current goal is to figure out how to split up the test suite into multiple pieces, as the current cycle time when developing tests is around 5 minutes which is too slow to be fun. And it has to be fun so you will want to contribute 🙂
Hello from my parents place, sitting on the border of Wales & England, listening to this excellent Victor Rice album, thinking of this time last year when I actually got to watch him play at Freedom Sounds Festival, which was one of my first adventures of the post-lockdown 2020s.
I have many distractions at the moment, many being work/life admin but here are some of the more interesting ones:
Playing in a new band in Santiago – Killo Karallo – recording some initial music which is to come out next week
Preparing new Vladimir Chicken music, also cooked and ready for release in April
I wrote a small program in Rust called cba_blooper. Its purpose is to download files from this funky looper pedal called the Blooper.
It’s the first time I finished a program in Rust. I find Rust programming a nice experience, after a couple of years of intermittent struggle to adapt my existing mental programming models to Rust’s conventions.
When I finished the tool I was surprised by the output size – initially a 5.6MB binary for a tool that basically just calls into libasound to read and write MIDI. I followed the excellent min-sized-rust guide and got that down to 1.4MB by fixing some obvious mistakes such as actually stripping the binary and building in release mode. But 1.4MB still seems quite big.
Next I ran cargo bloat and found there were two big dependencies:
I got ‘env_logger’ to shrink by disabling its optional features in Cargo.toml:
env_logger = { version ="0.10.0", default_features = false, features = [] }
As for ‘clap’, it seems unavoidable that it adds a few hundred KB to the binary. There’s an open issue here to improve that. I haven’t found a more minimal argument parser that looks anywhere near as nice as ‘clap’, so I guess the final binary will stay at 842KB for the time being. As my bin/directories fill up with Rust programs over the next decade, this overhead will start to add up but it’s fine for now.
It’s thanks to Rust being fun that this tool exists at all. It definitely easier to make a small C program but the story around distribution and dependency management for self-contained C programs is so not-fun that I probably wouldn’t even have bothered writing the tool in the first place.
The tech world is busy building “AI apps” with wild claims of solving all problems. Meanwhile it’s still basically an unsolved problem to get images and text to line up nicely when making presentation slides.
I’m giving a couple of talks at FOSDEM in February so i’ve been preparing slides. I previously used Reveal.js, which has some nice layout options (like r-stretch and r-fit-text), but pretty basic Markdown support such that I ended up writing the slides in raw HTML.
A colleague turned me onto Remark.js, a simpler tool with better Markdown support and a CLI tool (Backslide), but its layout support is less developed than Reveal.js so I ended frustrated at the work necessary to lay things out neatly.
In the end, I’ve built my own tiny tool based around python-markdown and its attr_list extension, to compile Markdown to Reveal.js HTML in a way that attempts to not be hopelessly annoying. It’s a work in progress, but hopefully I can work towards becoming less frustrated while making slides. The code is here, take it if you like it and don’t ask me any questions 🙂
Last week I attended OSSEU 2022 in Dublin, gave a talk about BuildStream 2.0 and the REAPI, and saw some new and old faces. Good times apart from the common cold I picked up on the way — I was glad that the event mandated face-masks for everyone so I could cover my own face without being the “odd one out”. (And so that we were safer from the 3+ COVID-19 cases reported at the event).
Being in the same room as Javier allowed some progress on our slightly “skunkworks” project to bring OpenQA testing to upstream GNOME. There was enough time to fix the big regressions that had halted testing completely since last year, one being an expired API key and the other, removal of virtio VGA support in upstream’s openqa_worker container. We prefer using the upstream container over maintaining our own fork, in the hope that our limited available time can go on maintaining tests instead, but the containers are provided on a “best effort” basis and since our tests are different to openqa.opensuse.org, regressions like this are to be expected.
I am also hoping to move the tests out of gnome-build-meta into a separate openqa-tests repo. We initially put them in gnome-build-meta because ultimately we’d like to be able to do pre-merge testing of gnome-build-meta branches, but since it takes hours to produce an ISO image from a given commit, it is painfully slow to create and update the OpenQA tests themselves. Now that Gitlab supports child pipelines, we can hopefully satisfy both use cases: one pipeline that quickly runs tests against the prebuilt “s3-image” from os.gnome.org, and a second that is triggered for a specific gnome-build-meta build pipeline and validates that.
First though, we need to update all the existing tests for the visual changes that occurred in the meantime, which are mostly due to gnome-initial-setup now using GTK4. That’s still a slow process as there are many existing needles (screenshots), and each time the tests are run, the Web UI allows updating only the first one to fail. That’s something else we’ll need to figure out before this could be called “production ready”, as any non-trivial style change to Adwaita would imply rerunning this whole update process.
All in all, for now openqa.gnome.org remains an interesting experiment. Perhaps by GUADEC next year there may be something more useful to report.
Team Codethink in the OSSEU 2022 lobby
My main fascination this month besides work has been exploring “AI” image generation. It’s amazing how quickly this technology has spread – it seems we had a big appetite for generative digital images.
I am really interested in the discussion about whether such things are “art”, because I this discussion is soon going to encompass music as well. We know that both OpenAI and Spotify are researching machine-generated music, and it’s particularly convenient for Spotify if they can continue to charge you £10 a month while progressively serving you more music that they generated in-house – and therefore reducing their royalty payments to record labels.
There are two related questions: whether AI-generated content is art, and whether something generated by an AI has the same monetary value as something a human made “by hand”. In my mind the answer is clear, but at the same time not quantifiable. Art is a form of human communication. Whether you use a neural network, a synthesizer, a microphone or a wax cylinder to produce that art is not relevant. Whether you use DALL-E 2 or a paintbrush is not relevant. Whether your art is any good depends on how it makes people feel.