Podcasts
If you’re into podcasts, the Blindboy Podcast is possibly the best one. Recent episode The State of the World begins on a pointy rock off the coast of Ireland that houses a 6th century monastery.

Then he raises the question of why, when the Russian government & the Russian military commit war crimes, US & European leaders apply punishing economic sanctions to Russia, and when the government and the military of Israel commit atrocities and war crimes, US & European leaders ask them nicely if they could please stop at some point, or at least commit slightly fewer of them.
On that note, I’d like to shout out the Bands Boycott Barclays movement in the UK — our politicians have failed, but at least our musicians aren’t afraid to follow the money and stand up for human rights.
Heisenbugs and spaghetti code
In computer programming jargon, a heisenbug is a software bug that seems to disappear or alter its behavior when one attempts to study it. (Wikipedia)
In the year 2018 I was passing time in Barcelona waiting to start a new job (and a new life, as it turned out). It was the middle of July and everyone had left for the summer. Meanwhile GNOME had recently gained a Gitlab instance and for the first time we could run automated test pipelines in Gitlab CI, so I set up initial CI pipelines for Tracker and Tracker Miners. (Which, by the way, are undergoing a rename).
Tracker Miners already has a testsuite, but in 2018 it was only run when someone decided to run it locally. Remember that our filesystem indexer is implemented as many GIO async callbacks, which means it is complex spaghetti code. These callbacks can fire in a different order depending on various factors. Tracker responds to filesystem notifications and disk reads, which are unpredictable. And of course, it has bugs — in 2018 nobody much was funding maintenance Tracker or Tracker Miners, and many of these would trigger, or not, depending on the execution order of the internal async callbacks.
So, many of the tests would just randomly fail, making the new CI rather useless.
Thanks to a lot of hard work by Carlos and myself, we documented and fixed these issues and the indexer is in a much better state. It was not much fun! I would rather be eating spaghetti than tracing through spaghetti code. I guess somewhere I made bad life choices.

In 2021, somehow not learning my lesson, I adopted the nascent openQA tests for GNOME OS that were developed by one of my Codethink colleagues. These have been running for 3 years now at a “beta” quality service, and have caught some interesting bugs along the way.
In late 2023 we noticed a seemingly random test failure, where the machine under test makes it through initial setup, but didn’t get to a user session. Let’s call this issue 62.
This issue reproduces a lot, when you don’t want it to, and rarely if ever when you do. Here’s a recent example. See how the initial setup stage (gnome_welcome) passes, but the transfer to the final user session never happens:
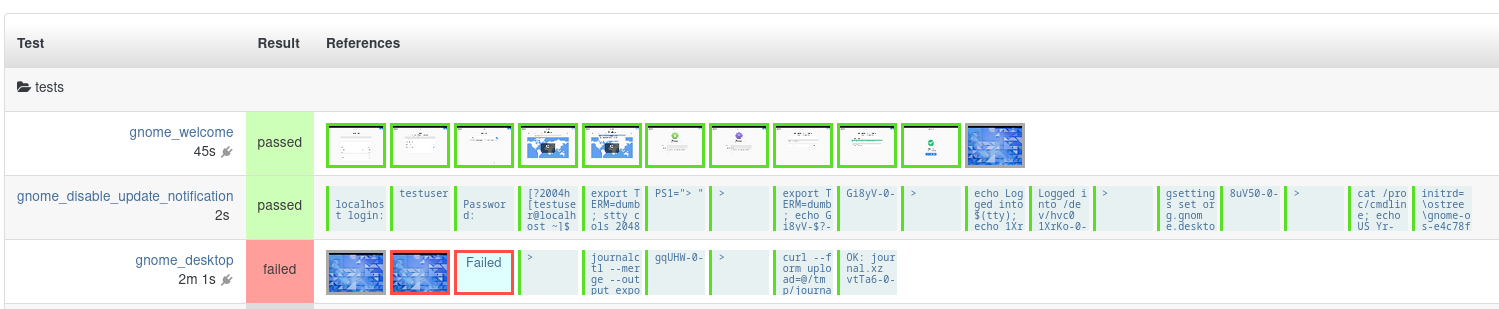
Random test failures make a test framework completely useless – if “test failed” can mean “your code is fine but fate is not on your side today”, then it’s not a useful signal for anyone. So for the GNOME OS automated testing to progress, we need to fix this intermittent failure.
GNOME OS runs many different processes during startup, which can start in whatever order the systemd daemon decides to start them, and can then start child processes of their own. No two boots are exactly the same. The graphical startup is driven by systemd, GDM, gnome-session, gnome-initial-setup and GNOME Shell, context switching between themselves hundreds of times following D-Bus message traffic. You could say that this is an extra large portion of spaghetti, with toxic meatballs.
As part of the STF engagement with GNOME OS, Neill Whillans spent a considerable amount of time comparing logs from good and bad boots, investigating the various processes that run at start-up time, and trying to catch the boot failure locally. I’ve tried my best to help as time permits (which it mostly does not).
Fundamentally, the issue is that there are two gnome-shell processes running, one for the initial-setup user and one for the new ‘testuser’ which should take over the session. GDM is supposed to kill the initial-setup shell when the new ‘testuser’ shell begins. This doesn’t happen.
We have a theory that its something failing during the startup of the new gnome-shell. The layout mechanism looks very complex, so its entirely possible that there is a heisenbug in there somewhere. As you would expect, enabling debug logs for GNOME Shell causes the issue to go away completely.
There’s a lesson here, which is that excessive complexity kills motivation, and ultimately kills projects. We could have done quite a lot in the last 7 months if not for this issue. Let’s all try to keep our code simple, debuggable and documented. We have succeeded in the past at killing overly complex abstractions in GNOME — remember CORBA? Perhaps we need to do so again.
What happens next? I am not sure – I think we may just have to give up on the end-to-end tests for the time being, as we can’t justify spending more of the current budget on this, and I’ve done enough volunteer debugging and documentation efforts for the time being – I plan to spend the summer evenings in a hammock, far away from any GNOME code, perhaps eating spaghetti.

There is a great tool https://rr-project.org that can make many Heisenbugs shallow by allowing complete execution traces to be saved for GDB based debugging. You can set breakpoints or watchpoints and “continue” or “reverse-continue” at will.
It can also be combined with sanitizers. Just yesterday I spent some 15 minutes to find the cause of MemorySanitizer errors (clang -fsanitize=memory). An uninitialized value was being copied twice, so I had to use two data watchpoints to find the fix. This bug could have been fixed easily without rr as well. I appreciate the X86 debug registers and the hardware watchpoints, because they allow me to follow the data flow without having to familiarize myself with the code.
https://github.com/rr-debugger/rr/wiki/Testimonials is worth reading. Note: By design, rr can be completely blind to some data races. I do not think that it is suitable for use in a CI pipeline. It is excellent in stress testing environments and when running regression tests on a developer’s machine.
I work on a RDBMS, and typically it is data races or crash recovery problems where rr allows the root causes of bugs to be found in minutes instead of weeks or months, sometimes years.
Thanks for the comment! I’m aware of RR, I’ve never successfully caught a bug with RR but I know a few colleagues who have done.
In this case, the bug only reproduces during early boot of a VM, and only in CI 😦
While rr can trace multiple processes, it indeed has some limitations, such as missing support of asynchronous I/O (both io_uring and the older io_setup/io_submit/io_getevents). Conditional branches and excessive amounts of thread or process context switching can make it extremely slow. The trace files can get very large, because they will have to record the results system calls. For example, any read() must copy the contents to the trace.
In a VM host, some performance counters would have to be enabled, or otherwise rr would not work at all. If you have identical executables and libraries (maybe also the kernel and its linux-vdso.so; I am not sure) and compatible enough CPUs, the rr replay traces might be portable between systems.
I guess that containers would also be out of the game for testing such early startup code.